Содержание
- Признание
- Вы правы — и нет
- Базовый минимум
- Что-нибудь лёгкое и с пользой
- ИИ-Агенты и инструменты в обвязках
- Антихрупкая кухня в Markdown-коммуналке
- Thesis as a Project
- Human in the Loop: Архитектор или читер?
- Видеоверсия
Признание
Всем привет, это Стас!
В конце марта я защитил диплом — об этом я писал в телеграм-канале. На «отлично». И на 89,3% оригинальности по Антиплагиат.ВУЗ. Теперь потихоньку работаю над тем, чтобы пристроить эту корочку в магистратуру — подробнее о планах. В свои-то тридцать два.
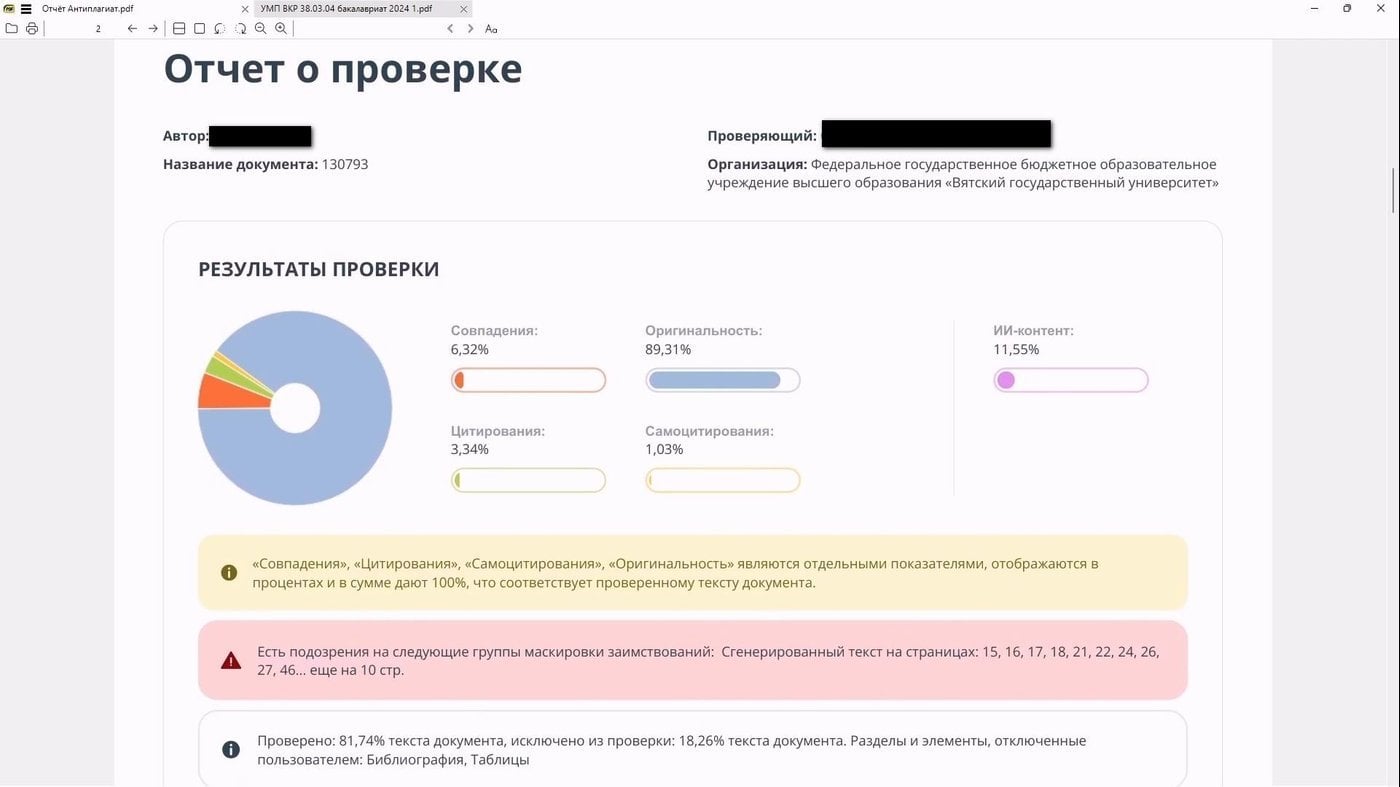
Всё ещё 11,55% маркеров ИИ, можно было больше постараться
Но сперва кое-что, в чём мне нужно вам признаться.
Во время подготовки своей работы я не открывал Word. И PowerPoint тоже. Кроме разве что самых финальных правок.
В библиотеку не ходил. За учебниками не сидел. В привычном понимании.
Клавиатуру использовал — не всегда.

Работа в этой папке действительно не моя. Рано плохо подумали, просто после защиты что-то выдали
В этом тесте расскажу «Как так получилось вообще?», «Что за агенты такие?» и «Как собрать вокруг себя систему из источников, файлов и ИИ». Без глянцевых презентаций, без FOMO, без инфобиз-клише про заработок с ИИ за выходные.
Деньги вы скорее будете тратить, но получать удовольствие и пользу в другом. Я просто покажу, что бывает и что пробовал сам. А там сами решите, нужно ли вам такое.
Когда я делал свою работу, я не знал и о трети похожих систем, которые нашёл во время подготовки этого материала. Так что у вас должно получиться даже лучше.
Вы правы — и нет
Я специально начал с крючка про диплом. Вы могли подумать: «Ну вот. Ещё один студент вставил промпт в DeepSeek и получил набор символов, который выдал за результат своего интеллектуального труда».
Как-то так на самом деле школьники и студенты готовят свои работы. А потом удивляются несуществующим цитатам и источникам
Понимаю. Скепсис абсолютно заслуженный. Потому что именно так многие и делают. Открыл чат в браузере, ввёл «напиши мне работу про природопользование в Кировской области, выдавай главу за главой», получил что-то похожее на текст. Источники выдуманы, логика разваливается. Но с расстояния двух метров выглядит как работа.
Преподаватели это видят и раздражаются, а система образования не очень понимает, что с этим делать. Сочинения в школе, рефераты в колледже, курсовые, новости в региональных пабликах — кругом нейрослоп. Но отмахнуться от этого уже не выйдет. По данным НИУ ВШЭ, около 90% российских студентов уже используют ИИ для учёбы. Девять из десяти. Британцы в своих отчётах пишут то же самое: в этом году 95%. Преподаватели, кстати, не отстают — 66% постоянно автоматизируют нейросетями отчёты и рутину.
Нобелевский комитет дал премию по химии в 2024-м создателям AlphaFold за предсказание структур белков. То, что люди десятилетиями делали в лабораториях руками, ИИ посчитал для более чем 200 миллионов последовательностей. Тут, конечно, стоит оговориться. AlphaFold — это не текстовый болтун, а вычислитель. К текстовым ассистентам стоит относиться сильно критичнее.
В январе OpenAI выкатили Prism — бесплатное рабочее пространство для учёных, которое само конвертирует наброски в LaTeX и подтягивает литературу. То есть вопрос «использовать или нет» уже как будто не стоит. Стоит другой: как делать это нормально?
Прошлой осенью я уловил в комиссионке за 60 рублей артефакт времени — «Кибернетика стучится в школу» Геннадия Воробьёва. Книга 80-х, но к удивлению — не советская утопия, а почти точный прогноз.
Автор описывал образование как кибернетическую систему, где ученик получает моментальную обратную связь, идёт по своему сценарию — и рядом компьютер-наставник, который подстраивается под темп каждого. Он писал, что машина должна взять на себя рутину проверки и подбора заданий, а учитель стать капитаном, а не контролёром. Сегодня мы называем это AI-тьюторами, адаптивными платформами и аналитикой обучения.
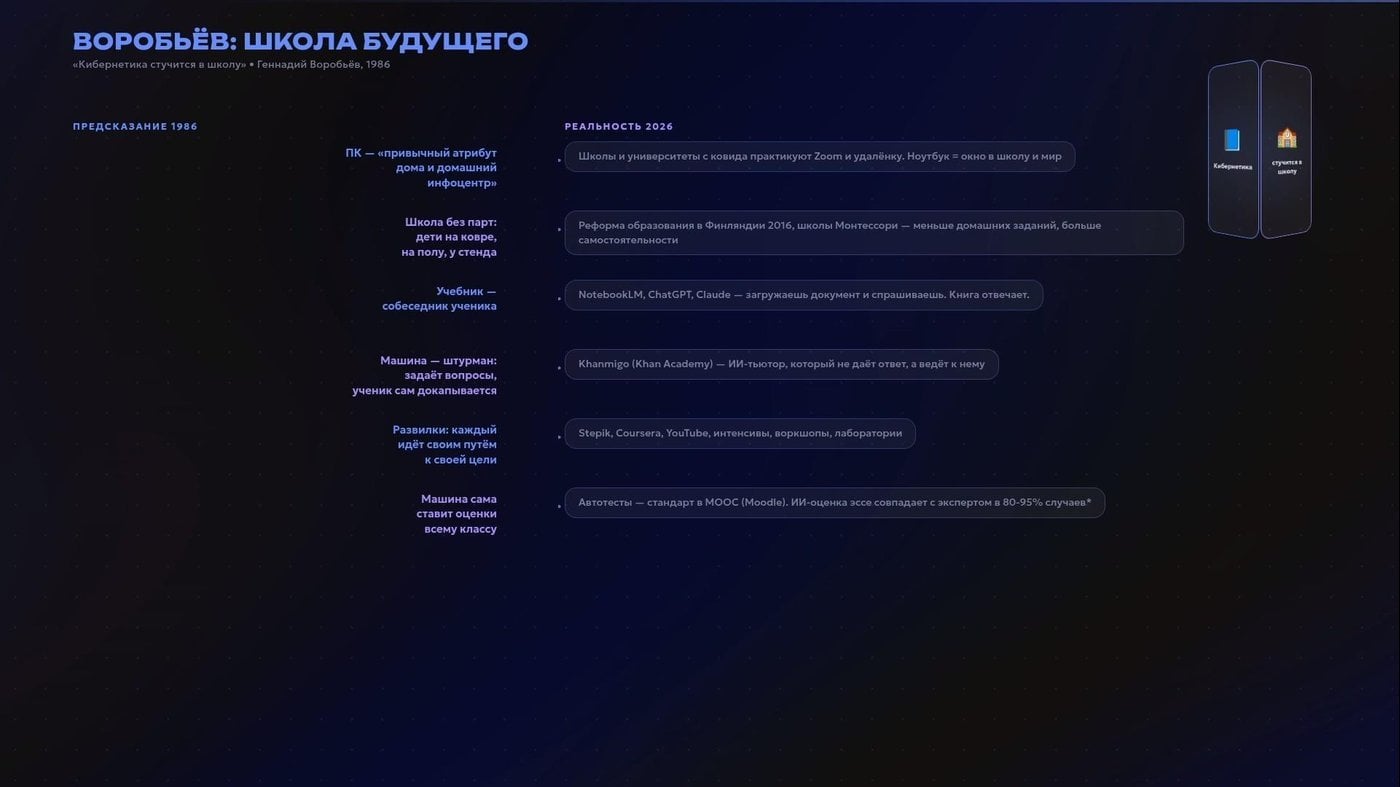
Просил GLM через EXA сравнить предсказания и сделать Remotion графику для видео
Модель может забрать рутину. А вот цели и решения — это к нам, не к ней.
Базовый минимум
Большая языковая модель (она же LLM) — это то, что в быту обычно называют «нейросетью для текста»: ChatGPT, Claude, Gemini, DeepSeek, Qwen и так далее. Она обучена на огромном массиве данных и умеет продолжать фразы так, чтобы это звучало убедительно.
Но убедительно — не значит правдиво. Поэтому модели галлюцинируют. Если точного ответа у них нет, они достраивают его тем, что похоже на правду. Это как человек, который пересказывает вам фильм, хотя сам его не смотрел. Интонация уверенная, структура есть, имена похожи на настоящие. Но потом выясняется, что половину он просто додумал по трейлеру, обложке и собственному ощущению жанра.
То, что модель видит прямо сейчас: ваш запрос, история переписки, загруженные файлы — всё это называется контекстом.
И он не бесконечен. У каждой модели есть «контекстное окно» — лимит на то, сколько текста она может удерживать в голове одновременно. Что не влезло — того для неё прямо сейчас как бы не существует. Но даже то, что влезло, модель читает неравномерно.
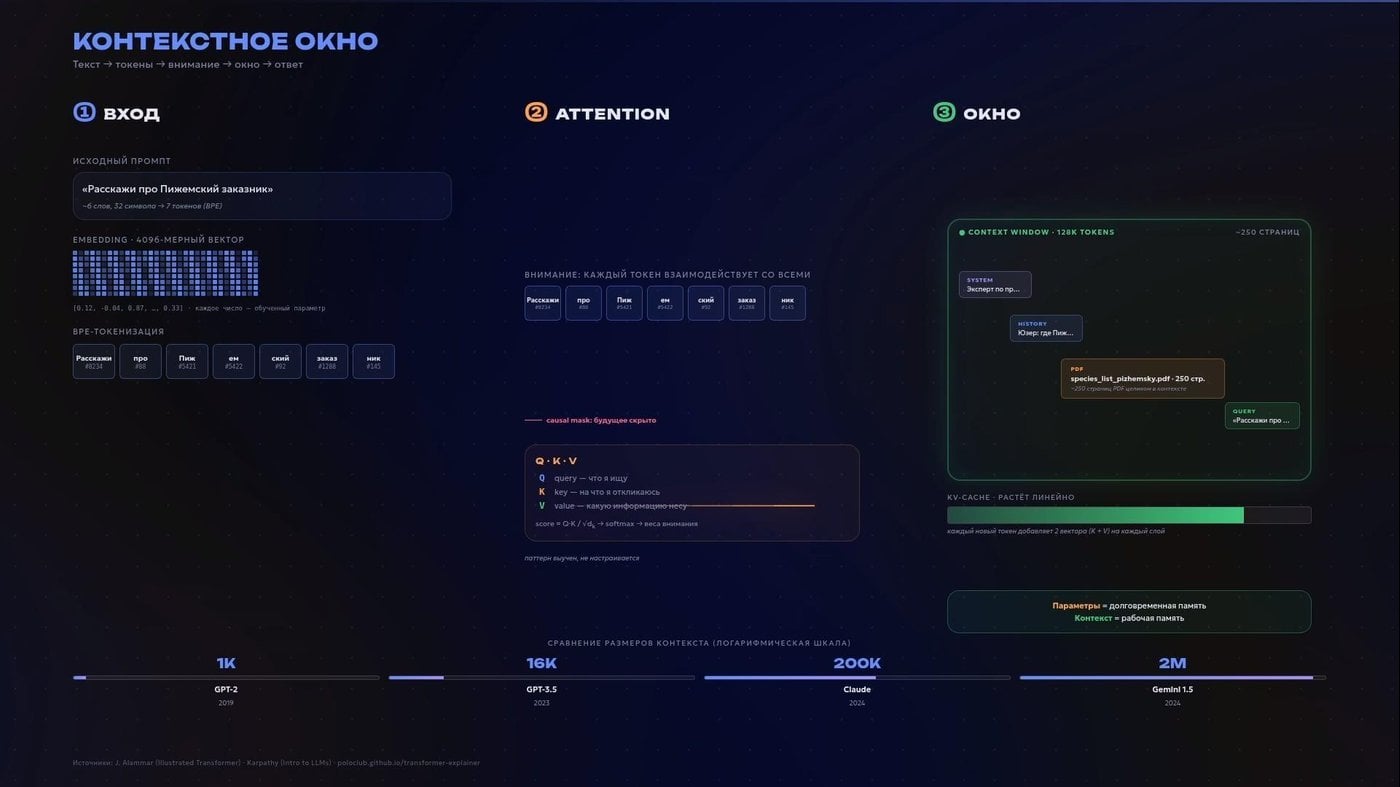
Ещё один Remotion-слайд
Ещё стоит учитывать, что модель не выдаёт один правильный ответ, она каждый раз выбирает из вероятностного распределения. Может, вы слышали про такой параметр, как «температура», который регулирует ширину этого выбора. Низкая температура — ответы предсказуемые и сухие. Это хорошо, чтобы превращать хаос в структуру. Высокая — разнообразные, рискованные и более творческие.
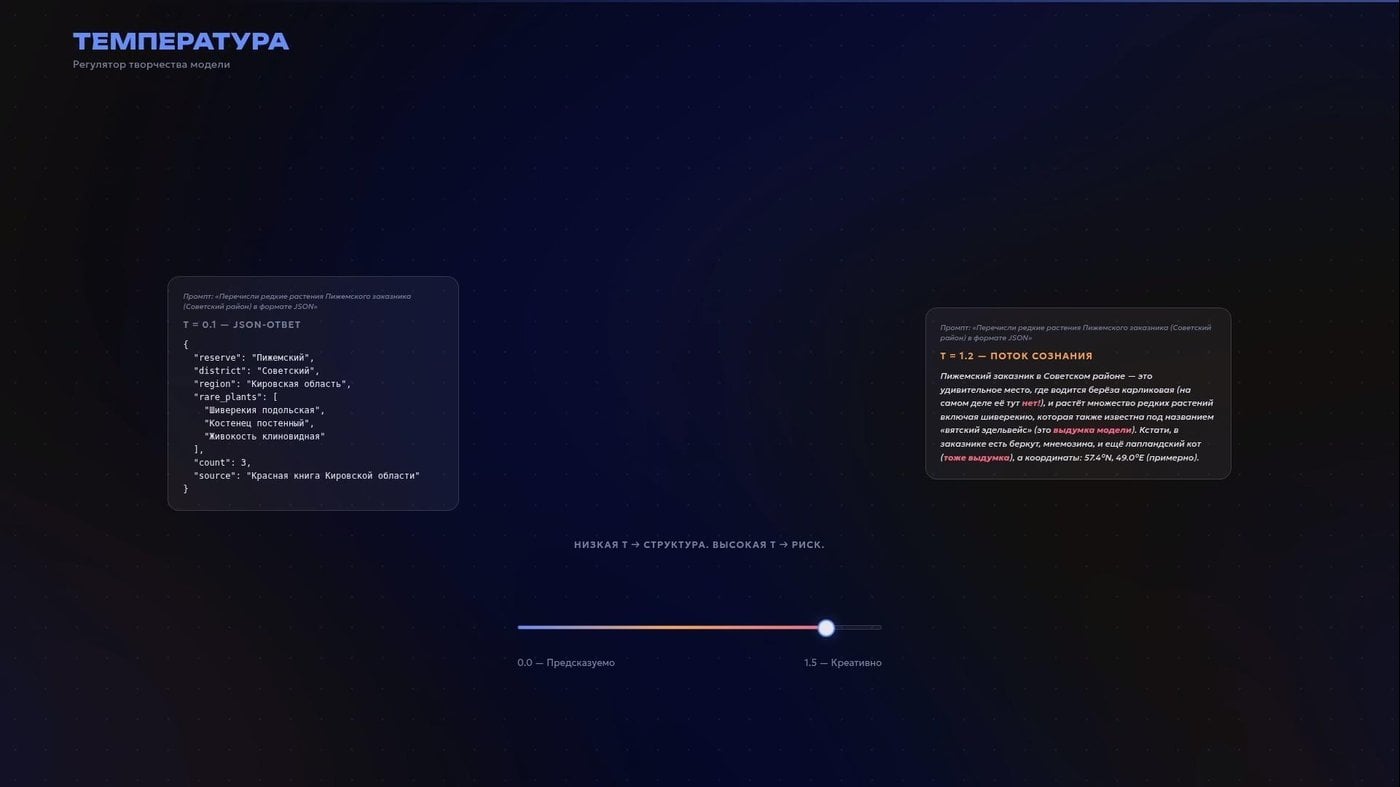
Structured output штука вообще полезная для автоматизаций
Если правда хотите понять, как это работает под капотом, посмотрите лекции Андрея Карпаты. Он стоял у истоков OpenAI, руководил AI в Tesla, подсадил весь твиттер на термин «вайбкодинг» и в мае ушёл в Anthropic заниматься R&D. Что за рок-звезда от мира нёрдов, вообще! Так вот, он прям хорош в умении объяснять эти вещи без инфобиз-налёта. Единственный нюанс — там местами нужно смотреть в код.
Если же код вас пока пугает, но понять суть хочется — горячо рекомендую канал 3Blue1Brown. На нём есть потрясающая визуальная серия про нейросети. Правда, некоторые анимации сначала покажутся попыткой визуализировать мысли математика, но уже через пару минут внезапно начинаешь понимать, что происходит.
Пока зафиксируем простое. Проблема зачастую не в том, «глупая» модель или «умная». Она работает с тем, что ей дали. Дали мутный запрос без поправки на миллиарды параметров — получили свой уверенный туман. Дали источники, жёсткие требования, примеры и возможность проверить математику калькулятором — разговор будет совсем другим.
Что-нибудь лёгкое и с пользой
Начнём с самого простого: не печатать всё руками.
Правки, мысли или куски текста я часто наговариваю голосом. Это правда бывает быстрее. Для этого выбираю Handy — открытую локальную программку для вызова speech-to-text по горячим клавишам. Среди моделей есть GigaAM от Сбера, которая для русского вроде как должна быть лучшей. Но я всё равно чаще использую Parakeet v3 от NVIDIA. Для моих задач хватает. Более известный платный облачный вариант — WisprFlow. Принцип тот же: говоришь и текст появляется прямо в блокноте или мессенджере.
Handy заменяет мне WisprFlow
Другая задача — расшифровать готовую запись созвона или диктофона из аудитории. Здесь я использую Vibe — тоже локальное открытое приложение с моделью Whisper. Принимает аудио, видео, ссылки с ютуба. Умеет выгружать текст в разные форматы, размечать по говорящим и суммаризировать через LLM, включая локальные.
Если не будет работать с видеоконференциями в Zoom, Discord, Яндекс.Телемост поможет виртуальный микшер: в один виртуальный вход отправляете и свой микрофон, и звук приложения. Жмёте запись — и поехало. Но, вроде, работает без костылей. И даже какое-то API даёт. Из проприетарно-облачных заметочников я бы сейчас смотрел на Granola, с ней меньше заморочек и легко подключать к системе как источник контекста, но к этому вернёмся чуть позже.
Полуторачасовой разговор с научруком перестаёт быть попыткой судорожно вспомнить по своим же кривым записям, что вообще имелось в виду. Теперь это сырьё, из которого можно вытащить конкретные задачи.
Есть и более киберпанковые вещи. Например, Omi — маленький открытый кулон-микрофон. Носишь на себе, он пишет разговоры за день и сам делает из них саммари. Звучит немного как антиутопия, да. Нужна этика и согласие собеседников. Интересно то, что его можно купить не только готовым: у проекта есть список компонентов с Али, прошивка и корпус, который можно напечатать на 3D-принтере. Но как факт: контекст для ИИ всё чаще начинается не с клавиатуры, а с прогулок и разговоров.

Сам не пробовал, поэтому не осуждаю
А что, если у нас не один текстовый документ, а целая гора материалов самого разного вида?
Недавно мне нужно было разобраться с книгой Тимоти Мортона про тёмную экологию. Дано: сама книга, запись ридинг-группы, аудиолекция и куча ссылок на статьи. Самый простой инструмент тут — Google NotebookLM. Загружаете свои источники, а модель отвечает строго по ним, ещё и показывая в интерфейсе пальцем, откуда взяла фрагмент.
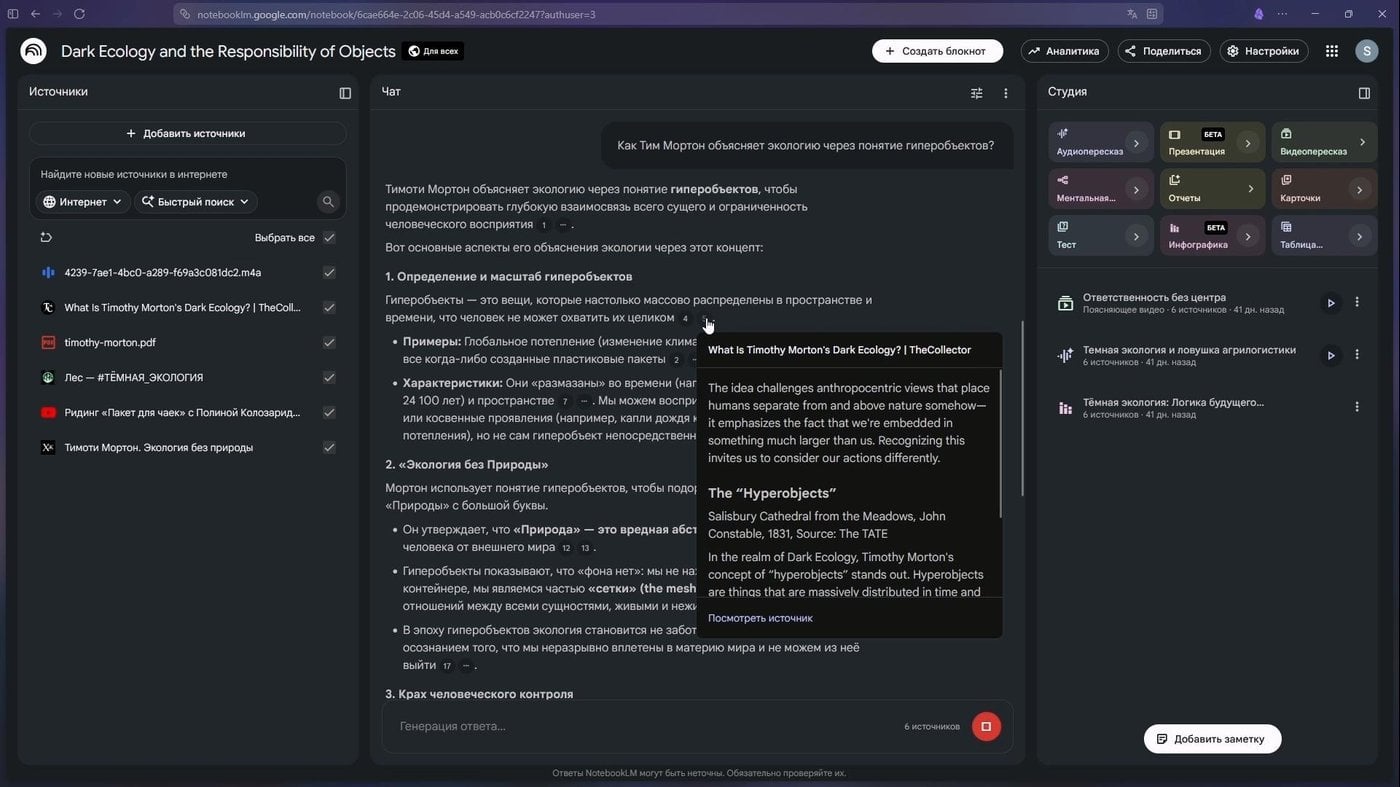
Добавил источников и радуется
Такой подход называют RAG или «генерация с поиском». Идея в том, чтобы сначала найти нужные куски в ваших файлах и уже по ним отвечать.
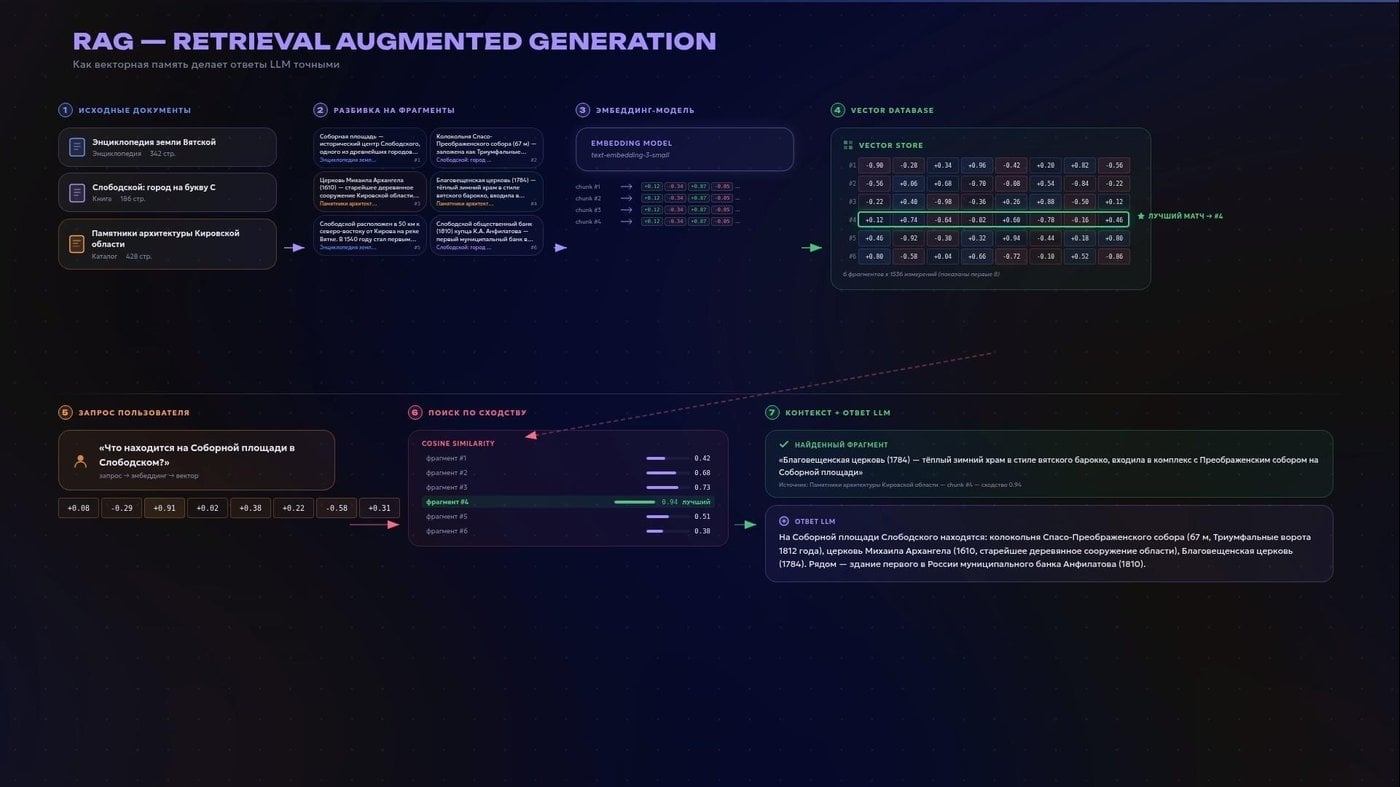
Векторная БД не обязательна, i know
Важно и то, во что результат можно переупаковать. Из одного набора материалов NotebookLM умеет делать инфографику, квиз, видеообзор или аудиоподкаст. Недавно появился режим дебатов, теперь ИИ-ведущие могут буквально спорить между собой прямо по вашим источникам. Ну и карточки для запоминания, которые потом через какие-нибудь браузерные расширения или сторонние скрипты легко превращаются в колоды для Anki.
Я чаще всего прошу сделать аудиообзор минут на двадцать. Утром, пока едешь куда-то на общественном транспорте или велосипеде, можно, что называется, «войти в тему». Это не гарантия абсолютной истины, но обычно это намного лучше обычного чата, который уверенно вспоминает мир из тумана.
Похожим образом я недавно поработал с интенсивом по ИИ-агентам от ШАД Яндекса. Финальное задание закрыл на 131 из 131 баллов. Прогонял лекции через транскрибатор, загружал в NotebookLM, вытаскивал определения, сам себя квизил. И уже потом забирал конспекты к себе.
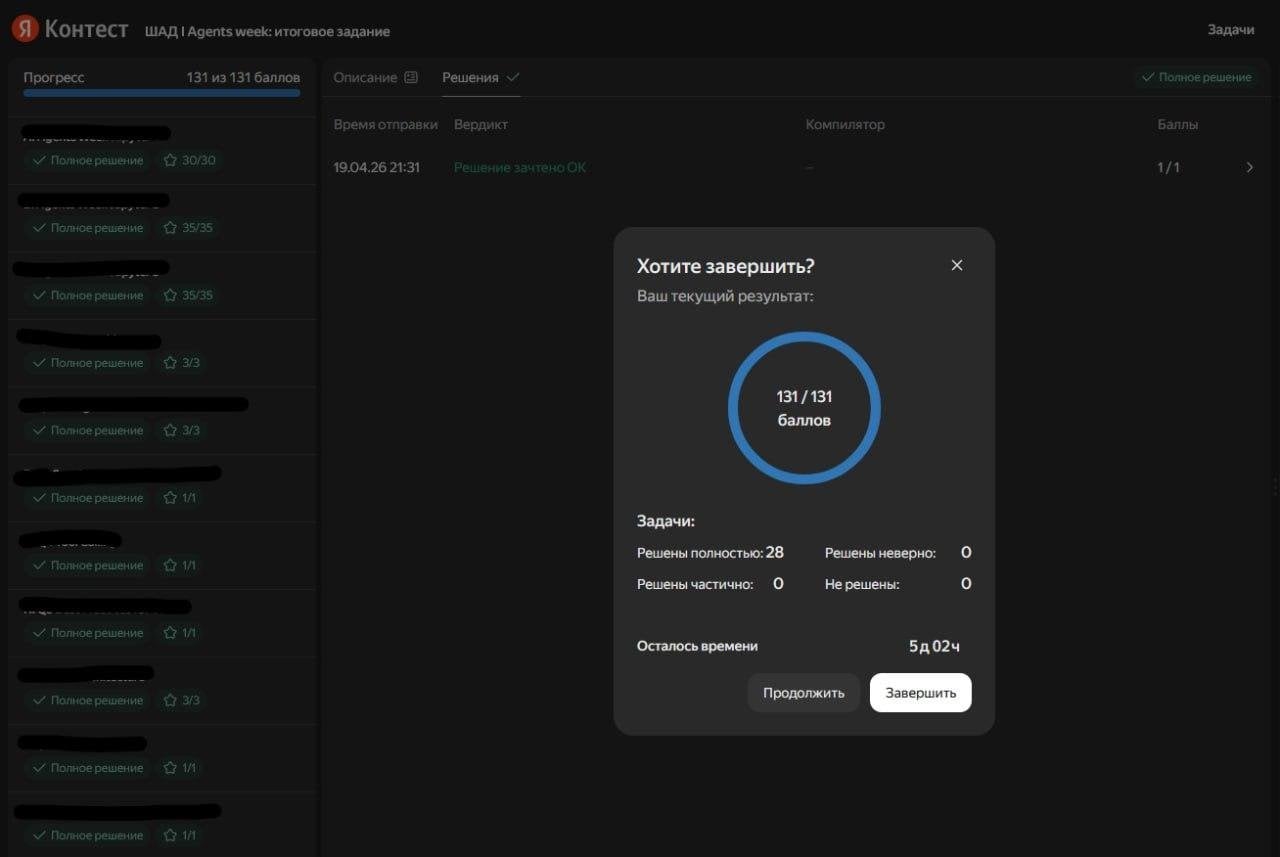
Внутренний «троечник», радовался, что теперь умеет так
Весь этот архив знаний живёт у меня в Obsidian — программе для заметок в формате markdown.
Markdown — это простой текстовый формат со структурой из решёток. Но важнее другое: это просто папка файлов на вашем компьютере. Её может открыть человек, сайт, поисковик по файлам или языковая модель. Внутри файлы связываются ссылками, образуя граф, и ты начинаешь видеть, как идеи цепляются друг за друга. Для академической работы это классно дружит с менеджером источников Zotero.
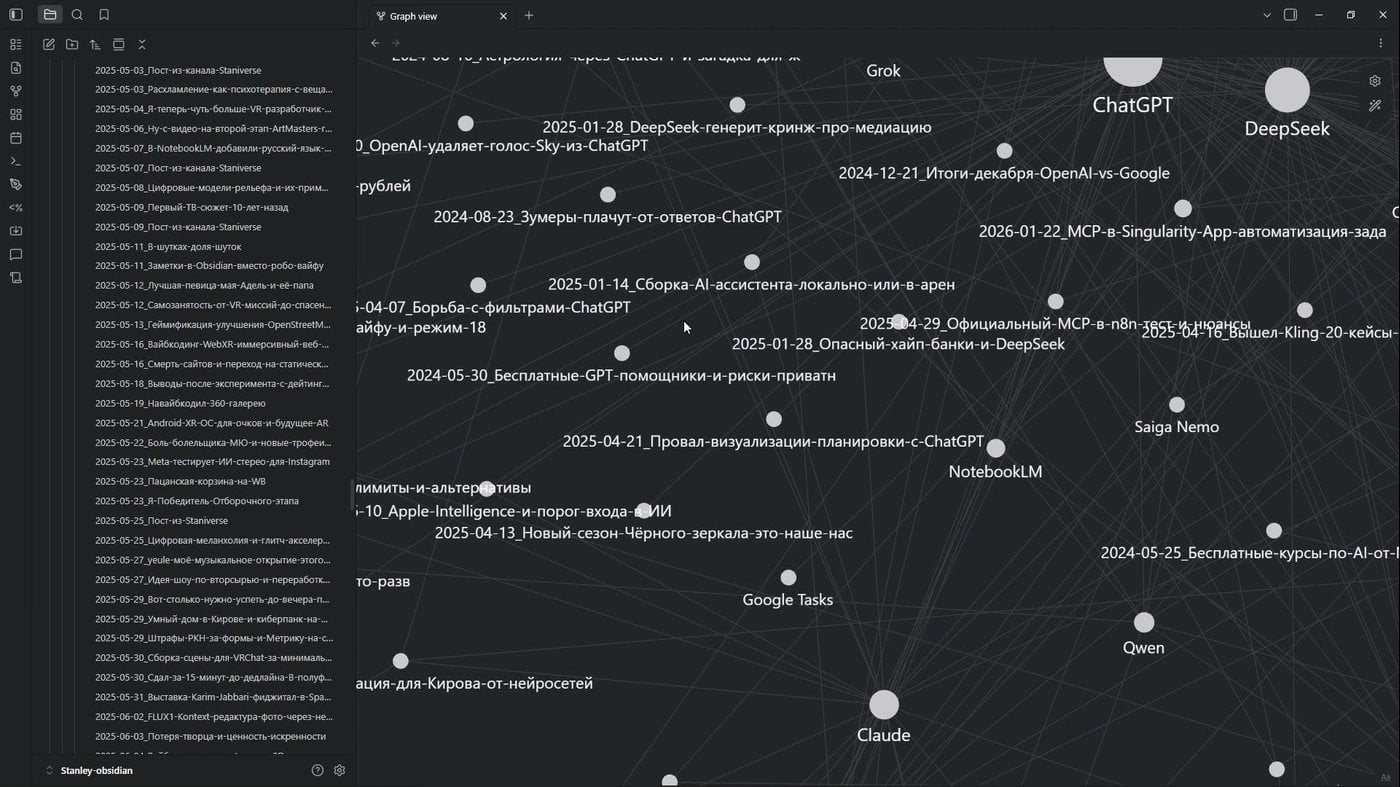
Размечал локальным Qwen-9B выгрузку своего канала и теперь могу показывать красивый граф
Если хочется вынести часть этого наружу — Obsidian можно превратить в сайт. Есть платный официальный вариант Obsidian Publish, а есть открытый Quartz, который генерирует статический сайт и бесплатно хостится на каком-нибудь GitHub Pages или GitLab, если имеете вопросики к Майкрософту.
Я недавно сделал таким способом сайт с базой из моего Telegram-канала. Разметил выгрузку постов, связал их между собой — получился цифровой сад. Не лента, а именно сеть идей.
Пошёл дальше, заморочился и прикрутил туда WebXR. Если открыть этот сайт с VR-гарнитурой, можно буквально летать внутри архива, путешествуя между постами, как между созвездиями. Зачем? Ну, во-первых, это красиво. А во-вторых, заметка перестаёт быть тупиком.
Окей, с этим разобрались. Добавляем следующий слой.
ИИ-Агенты и инструменты в обвязках
ИИ-агент — это не мистический цифровой сотрудник, который якобы за 20 долларов делает работу целой команды. Это языковая модель плюс правила, инструменты и право делать шаги. Чат просто отвечает. Агент может посмотреть файл, вызвать поиск, запустить команду, сохранить результат — и продолжить работу с тем, что получилось.
Тут важно не называть агентом вообще всё. Есть просто LLM-workflow — заранее заданная цепочка шагов. Приведу пример, где ИИ есть, а агентность не требуется. Допустим, у вас есть лендинг. Человек оставляет там заявку длинным текстом в свободной форме. Система ловит вебхук с этим текстом, отдаёт дешёвой языковой модели с чёткой задачей «вытащи отсюда имя, телефон, почту, суть боли и к какой она относится категории», затем аккуратно раскладывает структурированные сущности по ячейкам электронной таблицы, добавляет контакт в CRM, а менеджеру присылает короткое уведомление с выжимкой через бота в Telegram.
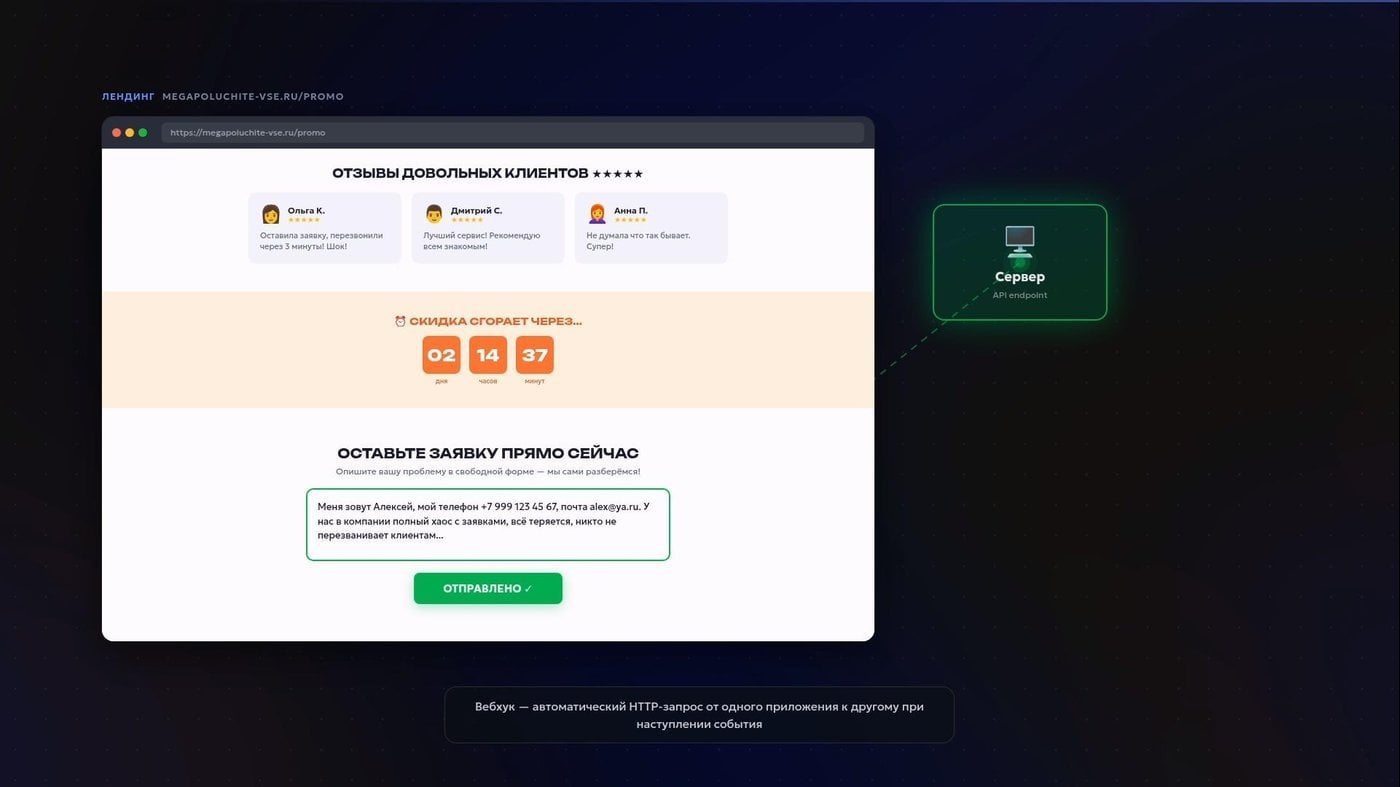
AIDA, AIDA, Лиды, Вебхуки
Всё это легко собирается в визуальных конструкторах. Я для такого люблю n8n — про него уже писал в канале. В отличие от облачного Make.com, его можно селфхостить — то есть развернуть на своём сервере, даже в закрытом контуре какого-нибудь предприятия. Это прям спасение, когда у вас есть юридические ограничения по обработке и хранению персональных данных граждан. Чужое облако или зарубежный виртуальный сервер тут не очень подойдёт.

И для таких понятных задач честный жёсткий конвейер работает сильно лучше, чем «автономный агент», который с умным видом уедет в закат и вернётся с чеком за токены.
Агентность — это другое. Рассказываю на примере базового паттерна ReAct (рассуждение и действие). Агент сначала думает вслух: «что происходит и что нужно сделать?». Потом вызывает инструмент. Смотрит, что получилось. И только потом решает следующий шаг. Думает — действует — наблюдает.
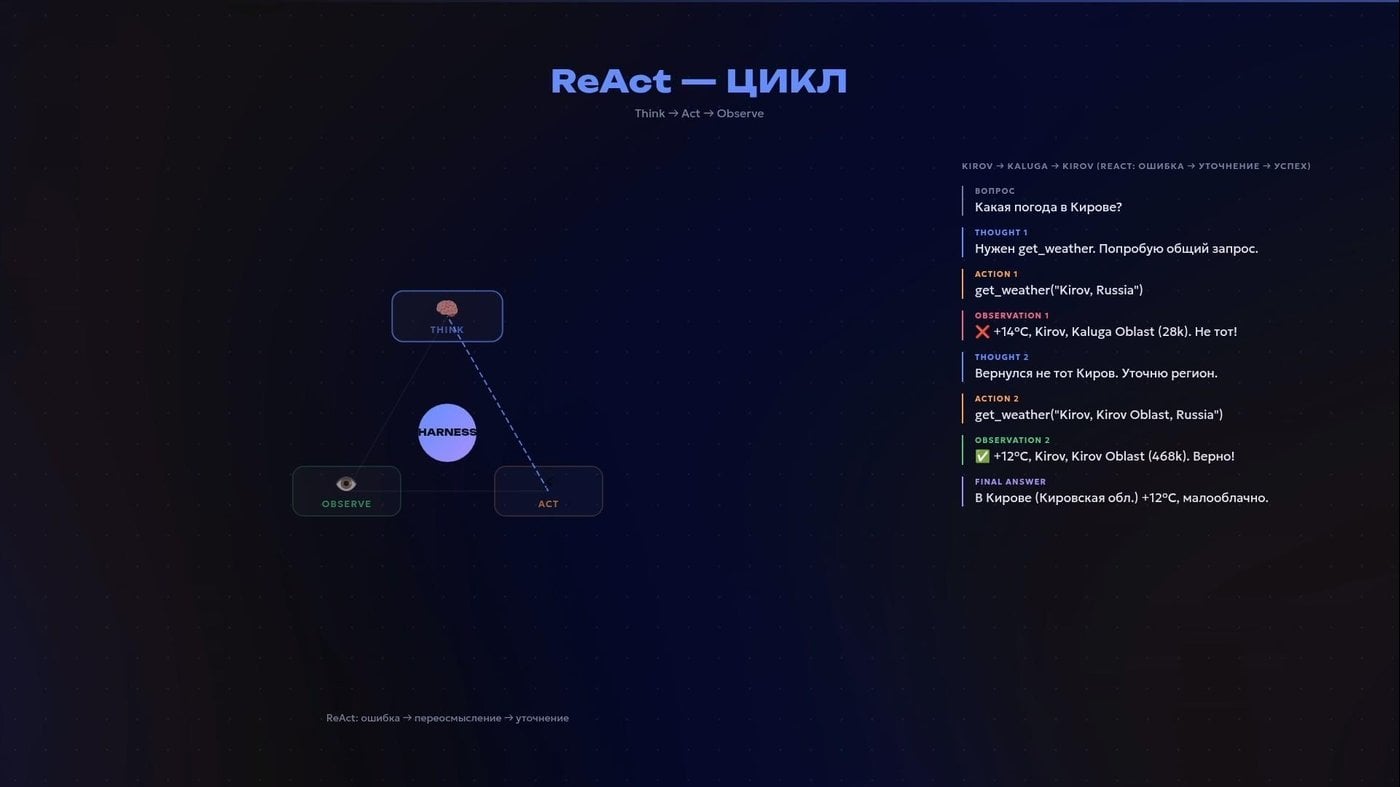
Личная боль, когда сервисы путают Киров в Калужской области и Кировской
Всё это вместе: промпт, инструменты, файлы, доступы — называется harness. Это прослойка, которая превращает LLM из болталки в рабочий инструмент. Хороший harness ещё и умеет маршрутизировать: простые задачи отдаёт дешёвым моделям, сложные — дорогим. Проверить, стоит ли будильник на 8 утра, не требует вызова гигантской дорогой Claude Opus. А проанализировать договор на пятьдесят страниц — уже может и требует. И так на каждой задаче экономия в десятки раз.
По сути, когда такой harness получает прямой доступ к вашей рабочей папке и терминалу, он начинает делать реальные вещи. Такие системы ещё продаются под ярлыком «кодинговые агенты». Не потому что они нужны только программистам, а просто потому что выросли из задач разработки. На деле же это универсальный комбайн для любой работы с текстом и файлами.
LLM сама по себе ничего не помнит. На первый взгляд кажется, что она похожа на Люси из фильма «50 первых поцелуев»: каждая новая встреча начинается будто с чистого листа. Но это лишь половина правды.
Точнее другая отсылка — «Мементо». Леонард не хранит воспоминания в голове. Перед каждой новой сценой он берёт пачку полароидов, разворачивает записки, смотрит на татуировки — и собирает из этого картину мира. Его память находится снаружи, не внутри.
Примерно и не очень точно так устроены современные агентные системы. Сама модель — не хранилище. Перед каждым запуском агент собирает для неё временное досье: историю диалога, заметки, файлы проекта, результаты поиска. Всё это складывается в единый контекст и отправляется в LLM.

Примерная схема того, как собирает запрос к API-модели
Память — не в модели. Модель — это читатель. Память хранится в архиве, а агент каждый раз раскладывает на столе нужные фотографии и записки перед тем, как читатель войдёт в комнату.
Вот тут на авансцену выходит наверняка мелькавший в ваших лентах Claude Code от Anthropic. Вы просто описываете задачу, а он читает файлы, предлагает правки и сам запускает нужные команды. Я предпочитаю гонять его через терминал — то есть через CLI, интерфейс командной строки. Звучит страшнее, чем выглядит, это просто управление текстом. Модели так даже удобнее.
При должном воображении — вашем или атакующего — пойманная галлюцинация может умудриться снести операционную систему, предварительно отправив папку с чувствительными фотографиями в рабочий чат. Не обязательно, что так будет, но имейте в виду. Приглядывайте, изолируйте по возможности.
А если нет официального CLI, как у того же NotebookLM, сообщество иногда пишет свои библиотеки. И агент начинает работать с сервисом как ему удобнее (на ваш страх и риск бана). То есть можно без построения своего сложного RAG автоматизировать и работу над исследованием, и генерацию того самого подкаста для утренней прогулки.
Когда агенту нужно получить данные или выполнить действие в интернете, он обращается к другой программе через специальный интерфейс для обмена запросами и данными. Такой интерфейс называется API. Например, в сценарии с лендингом через API CRM-системы создавался новый контакт, а через API Telegram-бота менеджеру отправлялось уведомление с краткой выжимкой заявки. Большинство современных сервисов предоставляют такие интерфейсы, чтобы с ними могли взаимодействовать другие программы.
Если нет ни CLI, ни API вообще, но автоматизировать какой-нибудь специфичный софт, рассчитанный только на человека с шариковой мышкой хочется — в ход идёт computer use. Агент сделает скриншот экрана, отправит его модели с поддержкой изображения на вход, поймёт, где нужная кнопка, кликнет, введёт текст, сделает ещё скриншот для проверки и пойдёт дальше размышлять над XY-координатами рабочего стола.
Всё ещё пугает терминал? У Claude Code, как и у Codex от OpenAI или открытого OpenCode, есть родные десктопные приложения.
Один из родных плагинов в десктопном Claude
Ещё один вариант — запустить помощника в неком универсальном редакторе с графическим интерфейсом, чтобы тут же открывать и редактировать файлы с текстами. Например, в VS Code. Или в VSCodium, если как и я не любите лишнюю майкрософтовскую телеметрию. Пусть вас не пугает ярлык «редактор кода». На вид это не страшнее Ворда: слева лежат файлы, по центру вы их читаете и правите, а сбоку или снизу сидит помощник.
Мы можете работать со всем этим так,…
…,если пугает такое. Хоть такое удобнее!
И прямо туда можно поставить официальное расширение того же Claude Code. Или открытое расширение Kilo Code — оно под капотом теперь работает на движке OpenCode и щедро делится доступом к актуальным китайским моделькам.
Больше открытого кода, меньше привязки к одному вендору! Закрытый софт — это когда корпорация полностью решает за тебя. Захотели — подняли стоимость подписки. Захотели — в один день обрезали доступ. А потом втихую дообучили модель на твоих же файлах и переписках, и продали твои данные какому-нибудь провайдеру рекламы.
Янис Варуфакис в книге «Технофеодализм» называет это превращением пользователей в цифровых крестьян. Звучит громко, но неприятное ощущение, когда кто-то дёргает рубильник просто потому что, сервис к которому ты привык становится значительно дороже с ухудшением качества и ты ничего не можешь с этим поделать — очень знакомое.
Если хочется максимального контроля над тем, куда уходят данные — есть полностью открытый OpenCode, который можно запустить локально. К нему подключаются локальные же модели вроде Qwen или Gemma через инструменты инференса: vllm, Ollama, llama.cpp из LM Studio. По железу такое потянет далеко не каждый компьютер, но есть небольшие модели, которые вместятся в игровую видеокарту.
Смотрел что влезет в мою 3060 с llmfit
А бывают и совсем малые языковые модели (SLM), которые запустит даже телефон. Актуально в лесу и где с мобильной связью что-то идёт не так. Например, в мегаполисе.
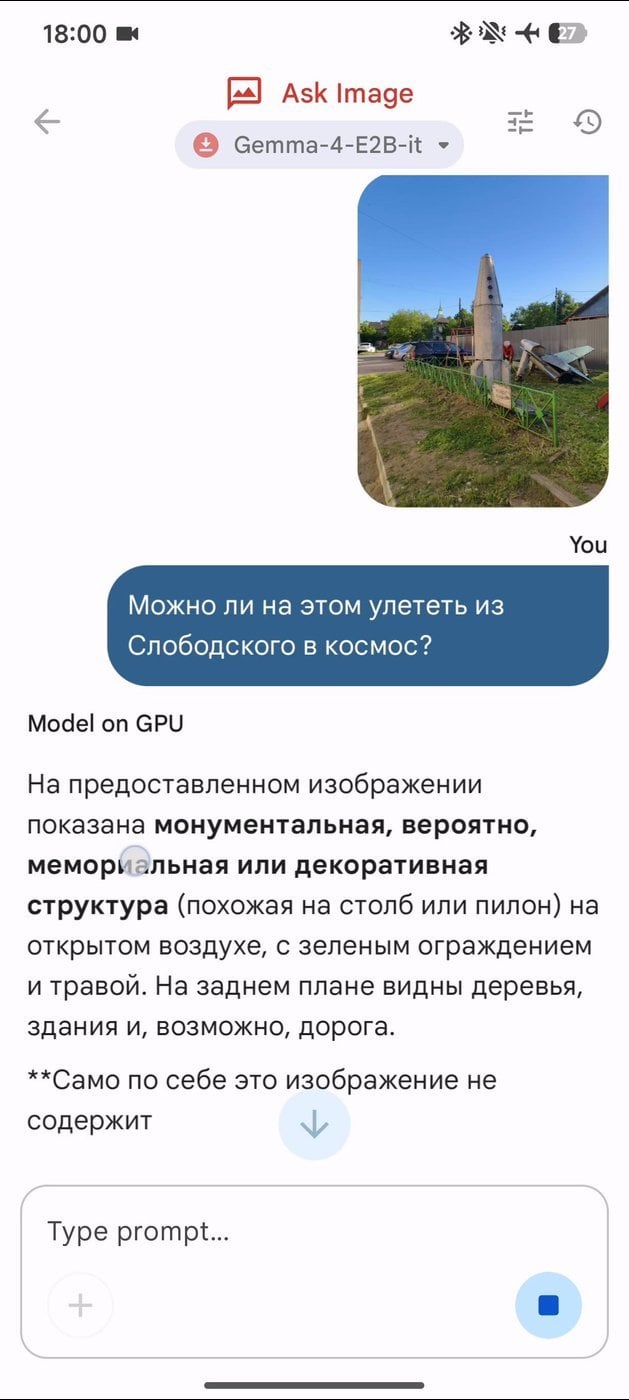
Gemma-4-E2B на моём Poco X7 Pro. Даже со зрением!
Если же хочется чего-то серьёзнее — можно собрать небольшой домашний кластер: несколько Mac Mini, NVIDIA DGX Spark. Или если бюджетно, то древние Radeon MI50 с горой серверной оперативки. Праздник конфиденциальности и независимости от внешней инфраструктуры.
Наблюдение из личного опыта: локальные модели из той же Ollama, как и дешёвые API-ключи китайских моделей, можно заводить напрямую в официальные приложения вроде Claude Code — если нравится именно их интерфейс. Я так прилично экономлю.
Спрятался в .env
Да, модели родом из Китая (Qwen, DeepSeek, GLM, Kimi, MiniMax) — кратно дешевле западных, причём даже для запада на западном же рынке. И при этом не обязательно медленнее: новый DeepSeek после перехода на чипы Huawei показывает отличную скорость и результаты на больших объемах. Сам я в начале года я успел взять годовую подписку на GLM за три доллара в месяц. Медленно, но работает. Таких цен уже нет.
Хотелось бы, чтобы цифровое развитие у нас тоже шло в эту сторону и конкуренцию, а не в сторону блокировок.
В папке проекта может лежать файл с базовыми инструкциями. А рядом — файлы навыков, так называемые Skills. Их пишут разработчики, энтузиасты из сообщества, да вообще кто угодно.
Вот как выглядит реальный навык humanizer, который убирает признаки ИИ-генерации из текстов. Это не сложный код, а просто человекочитаемый заголовок и текст на английском с разметкой, прямо как в нашем Obsidian. Можно и на русском, и на китайском — модели всё поймут.
Написать такое правда может любой. Настолько любой, что можно делегировать это самому ИИ. Существуют мета-скиллы, которые пишут скиллы. И агенты, которые создают других агентов. При желании можно запустить скилл для скилла, чтобы агент создал агента, который напишет скилл. А выполнит это всё модель, код для которой написала предыдущая версия этой модели. К маю 2026 более 80% кодовой базы Anthropic написал Claude.
Что из популярного нам предлагает сообщество? Например, Marketing Skills с десятками команд для SEO и аналитики. Но относитесь к агентам с такими навыками как к стажёрам, а не как к профи с большим стажем. Без вашей насмотренности и релевантого опыта оценивать и править их работу будет просто нечем.
Теперь про техническую часть подключения Granola и других инструментов. Существует открытый стандарт, через который ИИ-приложения подключаются к внешним данным — MCP (model context protocol). Для простоты его называют «USB-C для ИИ». Поисковики, базы данных, ваши файлы, документацию к чему-либо — всё можно подключить через один стандарт.
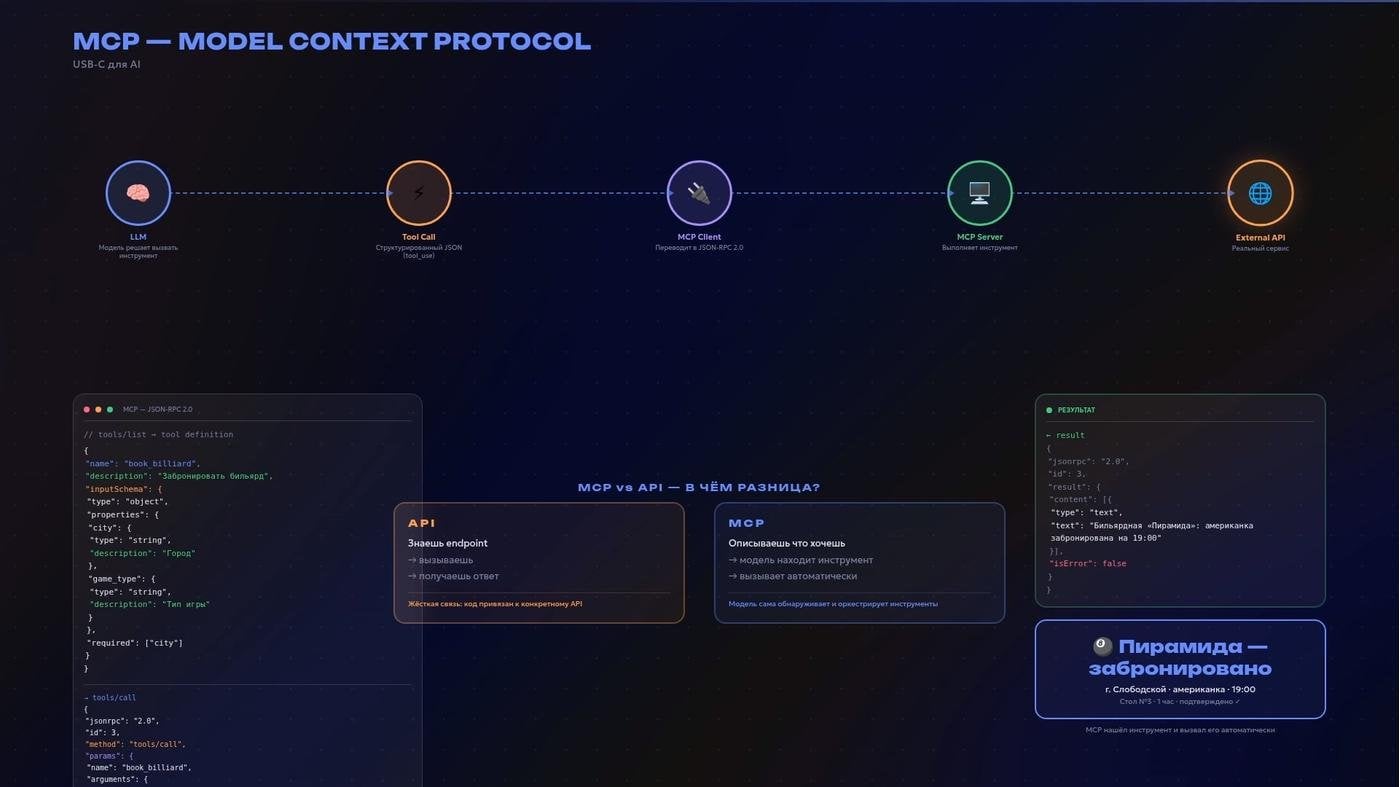
Попытка визуализировать МСР и отличие от API на примере брони бильярда в глубинке
У Claude Code есть фича на локальном MCP-сервере: она отправляет события в Telegram, Discord или iMessage. Дали агенту задачу, он отработал на компьютере дома — вы получили результат в привычном для себя месте, рядом с рабочими/семейными чатами и любимыми каналами с нишевыми мемами.
Работа во время прогулки по парку — вполне рабочая история. Если вас не смущает идея отвлекаться на работу во время отвлечения от работы. С другой стороны может вам настолько хочется трогать траву, что для связи со своими агентами вопреки собираешь и настраиваешь Meshtastic — open-source мессенджер, работающий вообще без интернета и вышек.
Есть и протоколы, по которым агенты разговаривают друг с другом, — [A2A]https://a2a-protocol.org/latest/) и ACP. A2A пришёл от Google, ACP — от IBM/BeeAI. В августе 2025-го они свелись под одним зонтиком Linux Foundation.
Есть на GitHub репозиторий проекта в помощь исследователю AutoResearchClaw. В нём идея проходит через пайплайн из 23-х стадий до готовой статьи с LaTeX. Работает и автоматически, и с человеком в петле (когда на ключевых шагах можно утвердить, поправить или откатиться). Так вот через этот самый ACP он подключается к любому агенту.
Про поиск стоит сказать отдельно.
Обычный гугл никуда не делся. Рядом существует специализированный поиск. Например, Google Scholar для научных статей. Искал там исследования про ИИ и XR, а наткнулся на профиль исследователя из Гонконга, который пишет про TikTok для филиппинских мальчиков и девочек-музыкантов, виртуальную любовь с ИИ или с аватарами в VRChat. У человека работа просто работа мечты!
Вот такое во благо науки я б пописал!
Дальше — гибридные решения вроде Perplexity AI, которые собирают ответ со ссылками. А за ними то, что называют Deep Research. Модель разбивает вопрос на подзадачи, ходит в веб, сопоставляет источники и собирает отчёт. Хороший способ быстро составить себе карту местности по незнакомой теме.
В последнее время я использую Exa AI и Parallel AI, у обоих щедрые бесплатные планы и возможность поиска строго по академическим источникам. Если хочется держать всё у себя на сервере — есть открытые GPT Researcher, Searcharvester, DeerFlow 2.0 от ByteDance, Tongyi DeepResearch от Alibaba. Большинство self-hosted вариантов требует Docker — на деле это одна команда docker compose up из папки распакованного архива, и всё поднимается само. В крайнем случае поможет привычный чат или самозанятый-фрилансер.
Выбирайте такого, у которого высокий ценник, сайт-визитка не по AIDA, но с WebXR-графом. И с Telegram-каналом, считайте саморекламным мгновением
Есть ещё отдельная ветка — не про поиск информации, а больше про эксперименты в машинном обучении. То есть агент не просто читает где-то что-то, а сам пробует разные варианты и проверяет, что реально работает лучше.
Для этого нужно заранее определить метрики качества, дать безопасную среду для экспериментов, вести журнал изменений и сохранять только те решения, которые действительно улучшают результат.
Из примеров — AutoResearch вашего нового (или старого) знакомого Андрея Карпаты. Развивает эту идею Multi-Agent AutoResearch: один агент ищет гипотезы, другой планирует эксперименты, третий убирает дубли, остальные запускают тесты и собирают метрики. В итоге исследование разбивается на набор специализированных ролей.
Описанное выше — это агенты под задачу. Но есть и другой класс — постоянный персональный агент, который просто живёт рядом.
«Королём» хайпа начала 2026-го на GitHub стал OpenClaw. Меньше чем за полгода проект набрал почти 380 тысяч звёзд. Он обогнал React — библиотеку для интерфейсов, на которой написана изрядная часть современного веба, — и само ядро Linux, которое в составе того или иного дистрибутива встречается везде: от умных холодильников до самых дорогих дата-центров.
Время покажет, насколько этот результат переживёт хайп. Мне кажется, сегодня на звёзды лучше смотреть в телескоп. Или в Space Engine. Искать что-то действительно новое в трендах гита теперь невероятно сложно — всё наглухо забито проектами, в описании которых обязательно висит магическое заклинание «ИИ-агент», ну или «harness».

Всем рекомендую залетать в чёрную дыру с VR-режимом
Порой удивляешься, кто залетает в эту тему. Буквально на днях PewDiePie представил Odysseus — собственный AI workspace с агентным harness. После публикации видео о релизе, проект всего за пару дней собрал более 30 тысяч звёзд на GitHub.
В чём идея OpenClaw и подобных проектов? У вас может быть несколько независимых агентов, каждый живёт в своей папке. Именно файлы в этой папке собирают личность агента, и при должном подходе в комбинации с другими источниками памяти возникает ощущение, что он знает о вас и ваших проектах годами как никто другой.
OpenClaw подключается к Telegram, Discord, WhatsApp и ещё много к чему. Отдельно выделю поддержку протокола Matrix, который можно поднять на своём сервере для максимальной приватности и использовать с клиентом Element.
Но можно просто поставить telemt на дешёвый зарубежный сервер и продолжить пользоваться лучшим мессенджером Telegram. В его майском объявлении боты научились общаться с другими ботами и отвечать за вас в личке. Что небесполезно для тех, кто что-то продаёт или оказывает услуги. На том же любящем постоянно придумывать новые и повышать текущие комиссии за всё Авито, ИИ-автоответчики с подключенными знаниями о вашем предложении взлетели потому, что скорость ответа решает не уйдёт ли клиент к конкуренту.
В Китае сотни людей готовы стоять в очередях, просто чтобы им помогли поставить OpenClaw на ноут. В прессе это безумие называют «вырастить лобстера» — TechRadar и Fortune разбирали этот феномен. И не обходится без историй про начальников, которым нужно видеть, что «ИИ внедрён», и ввести KPI по решённым с агентами задачам. С разных концов света. Правда, магии не происходит, если данные раскиданы, процессы ручные, а задача — просто «делай что-нибудь с ИИ».
Ещё один пример персонального агента, который мне нравится — Hermes от Nous Research. Не столько из-за набора функций, сколько из-за того, как он накапливает опыт. И какого визуального стиля раздаёт его сайт.
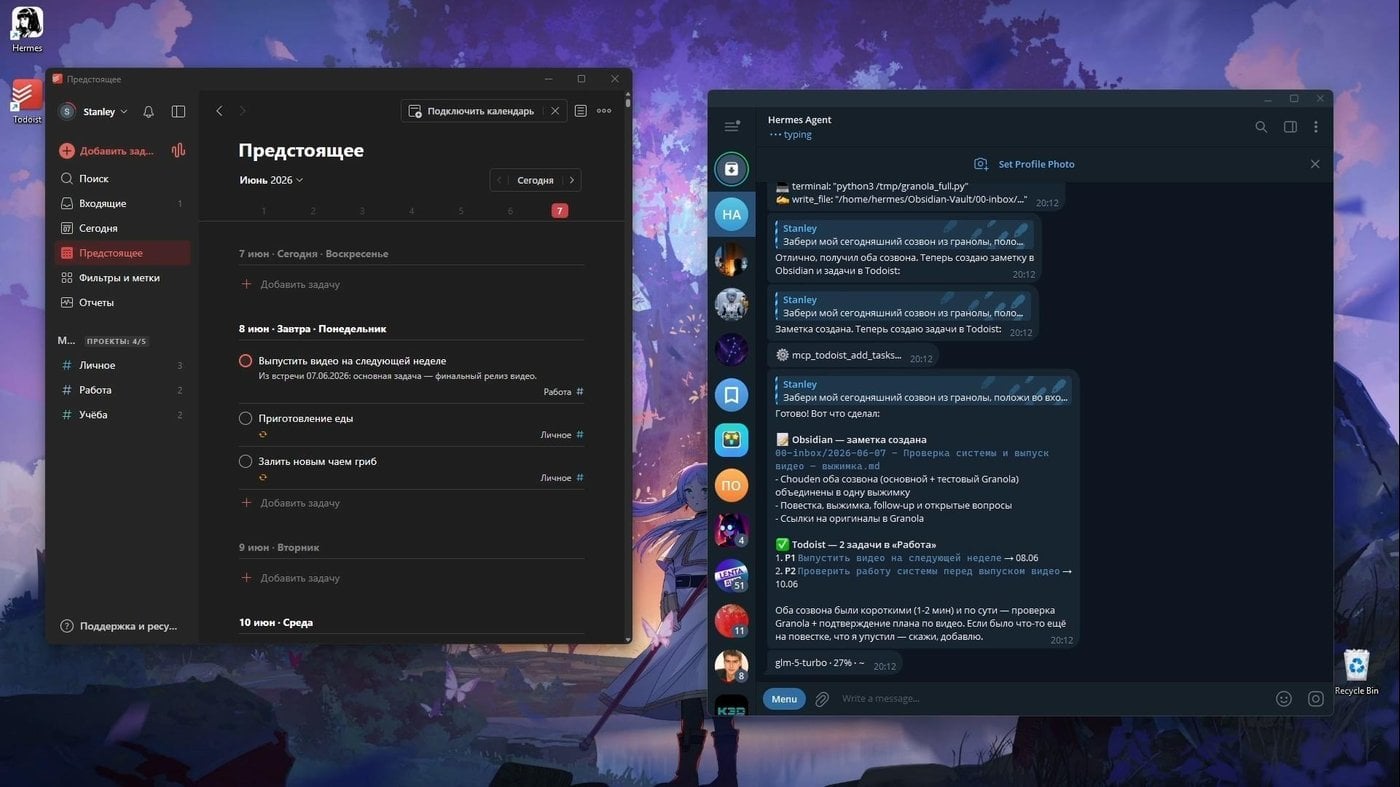
Учились с Hermes подключаться к той же Granola и API Todoist, чтобы забирать одного из другого, разбирать на таски и складывать транскрипты в Inbox Obsdiain
Агент ведёт живую память о пользователе и окружении, регулярно пересматривает её по ходу работы и сам решает, что важно сохранить, а что выбросить. Если пришлось разбираться с новой инфраструктурой или сервисом — он может сохранить удачный подход как навык, что-то вроде заметки на полях, и вернуться к ней в следующий раз. Со временем таких заметок-скиллов становится больше, и агент всё реже начинает с нуля.
Дополняет это внешняя долговременная память вроде Honcho — она хранит не только способы решения задач, но и контекст вокруг них: предпочтения, особенности проектов, накопленные наблюдения. Продолжая аналогию с «Мементо», Honcho не просто складывает полароиды в коробку, а перед каждой задачей достаёт несколько тех самых, которые могут оказаться полезны именно сейчас. При этом оптимизируя контекстное окно и экономя расход токенов.
Я предупреждал в начале, что после этого видео вы не научитесь зарабатывать на ИИ, а скорее захотите потратить на эксперименты с этим всем какое-то количество времени и денег! С Hermes, как и с OpenClaw можно уложиться где-то в 2500 рублей/месяц на 20 долларовую подписку на ChatGPT с Codex и арендой виртуального сервера. Claude за 20$ не рекомендую, слишком быстро спотыкаетесь в лимиты и риски банов за подключения к неродным сервисам. OpenAI к этому относятся сильно лояльнее. Пока.
А виртуальный сервер можно заменить на стоящий дома МиниПК или одноплатный компьютер типа Raspberry Pi. Даже для моей старенькой Model B+ с 512 МБ оперативной памяти нашёлся PicoClaw, занимающий меньше 10 МБ этой самой RAM. Так можно дать вторую жизнь 12-летней железке, завалявшейся на полке.
Если хочется строить своё — смотрите на фреймворки типа LangChain, LangGraph, PydanticAI, Mastra, OpenAI Agents SDK и другие. Для первого шага и персонального использования это избыточно.
И эт самое. Добро пожаловать в ощущение, что мы где-то между фильмом «Она», Джарвисом Тони Старка и зарёй карманных ИИ-компаний из одного человека!
Про последнее — можете глянуть Paperclip, штуку для оркестрации команд ИИ-агентов. Там можно собрать типа-компанию ИИ-агентов с оргструктурой и бюджетами.
Антихрупкая кухня в Markdown-коммуналке (Obsidian как единый источник истины для ИИ)
У нас уже есть голос, расшифровки, источники, агенты с инструментами, локальные и облачные модельки. И сейчас всё это напоминает какую-то коммуналку. Каждый инструмент сидит в своей комнате, живет своей жизнью, со своей памятью и базой данных. Но было бы классно, если бы все они периодически встречались на общей кухне.
Фокус в том, что даже если инструменты абсолютно разные, их можно заставить договориться. Вы просто создаёте переносимый слой контекста, общее пространство, куда все агенты складывают результаты и откуда берут нужное. И этим местом, этой «общей кухней», может стать Obsidian vault. Точнее — та самая папка с текстовыми файлами на вашем диске. Которые можно и нужно редактировать.
Чтобы агенты имели к ней доступ, этот vault (или только нужную его часть) c вашего компьютера можно синхронизировать с тем же виртуальным сервером через простой Syncthing. Если вы не умеете его настраивать — просто попросите своего агента помочь, он напишет вам пошаговую инструкцию или вообще сделает всё за вас, если достаточно прав.
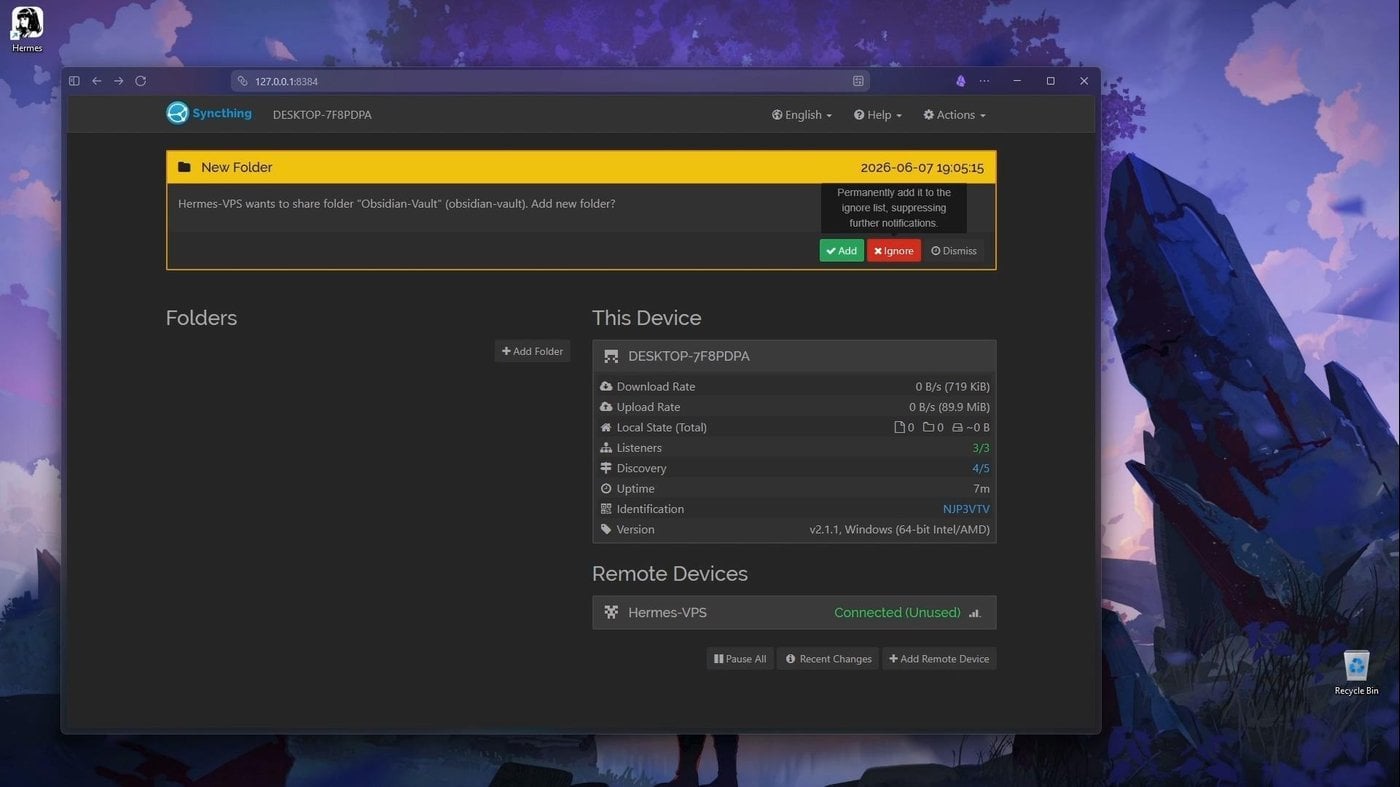
Договорился с Hermes синхронизировать мой Vault и получил инвайт на шаринг
Как это выглядит на практике? Допустим, я еду в автобусе, смотрю в окно, и мне в голову приходит классная тема для поста. Раньше пришлось бы доставать телефон, открывать браузер, плодить вкладки. Сейчас можно делать иначе.
Я просто открываю Telegram и пишу сообщение своему личному агенту, например, тому самому Hermes, о котором рассказывал чуть раньше. Говорю: «Слушай, есть такая мысль, сделай ресёрч по теме и подготовь черновик публикации». На этом моё участие заканчивается, я еду дальше.
Что в это время сделает агент? Он поресёрчит Интернет знакомыми вам инструментами, соберёт фактуру. Затем по тому самому синхронизированному каналу обратится к моей папке, и аккуратно сложит найденные источники в заранее оговоренном формате в заранее оговоренном месте. А затем из этих же источников выжмет суть и положит готовый черновик для канала в папку Drafts. Даже учтёт мой ton of voice.
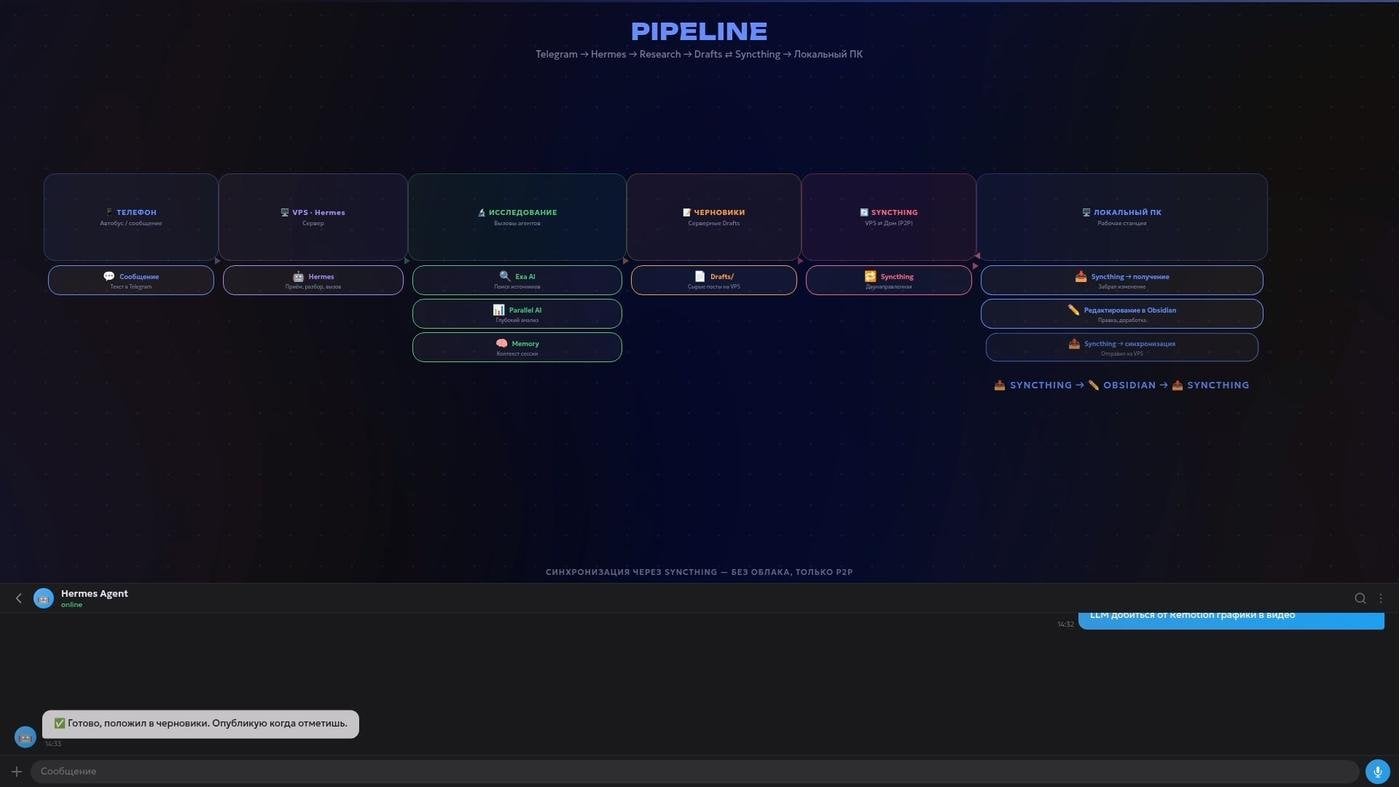
Пайплайн кейса с черновиком поста
Когда я доберусь до компьютера, у меня уже будет готовая фактура и черновик, с которым можно работать под светом распечатанных на 3D-принтере светильников с умными лампами. И на этом магия вечера не закончится. Агент запомнит во внешнем слое, какие темы мне интересны в принципе. Более того, я могу настроить процесс так, чтобы когда я закончу править этот черновик и поставлю в метаданных галочку ready_to_publish — текст нужно будет забрать. Он увидит этот триггер, заберёт файл, опубликует пост в нужные соцсети через Postiz (или напрямую по API, где так можно), предварительно адаптировав под их форматы. Всё это при минимальном моём участии.
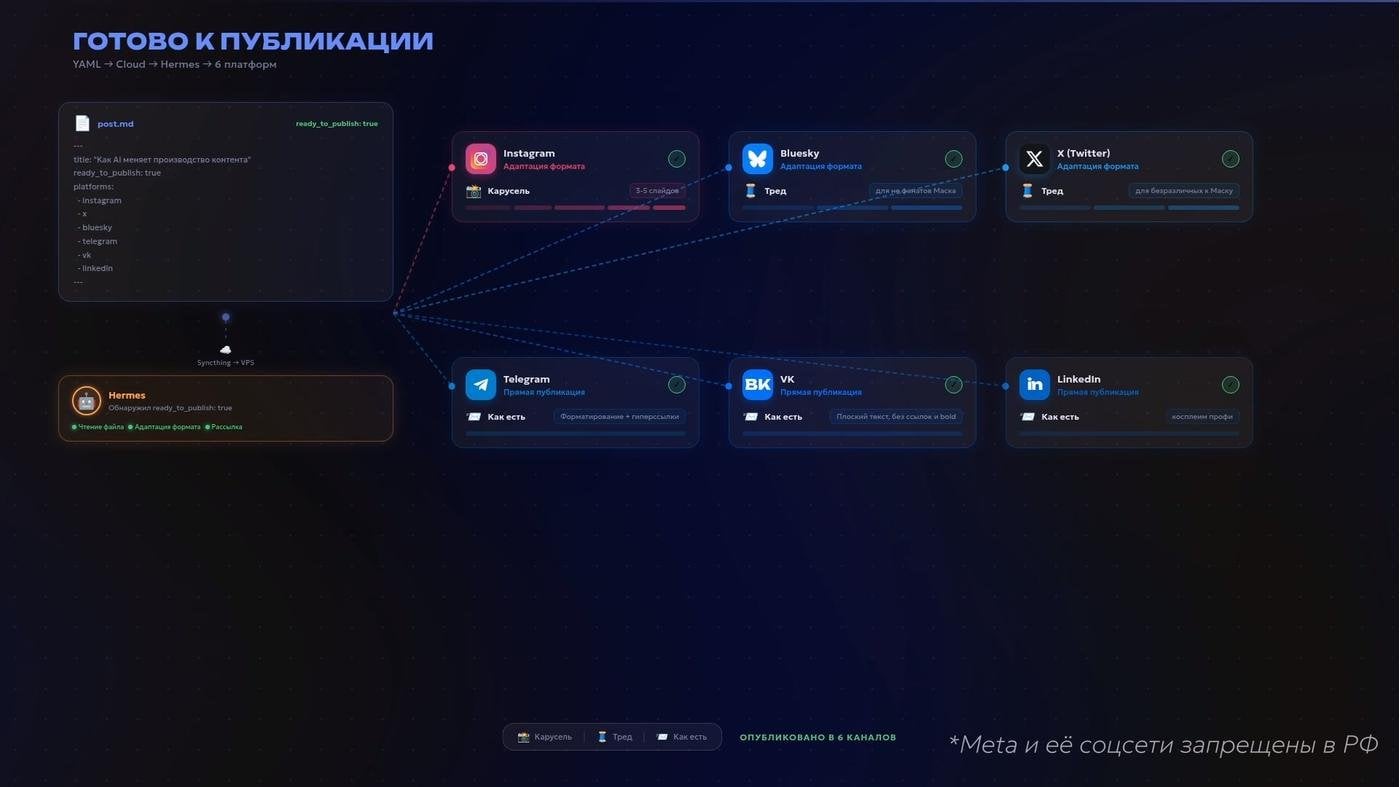
Нужно учитывать особенности и форматы соцсетей для кросспостинга
Например, вы пилите веб-приложение. Ваш Claude Code заглядывает в папку «Backlog» проекта, сверяется с задачами, пишет код и затем сам обновляет прогресс прямо в markdown-файле беклога. В это же время Hermes тихо собирает мне подборку интересного и отправляет мне сформулированные по канонам «Джедайских техник» задачи в Todoist. Тем временем агент, который помогает с исследованием для следующего живёт, живёт только в папке «MetaverseVideo» и вообще не подозревает о существовании вашего кода или постов для Telegram. Они работают параллельно в одном пространстве и не ломают друг друга.
А чтобы контекст был ещё полнее, отличная затея — настроить фоновые процессы, которые будут автоматически выгружать данные из ваших внешних трекеров и сервисов, преобразовывать их в аккуратные markdown-таблички и складывать в Obsidian.
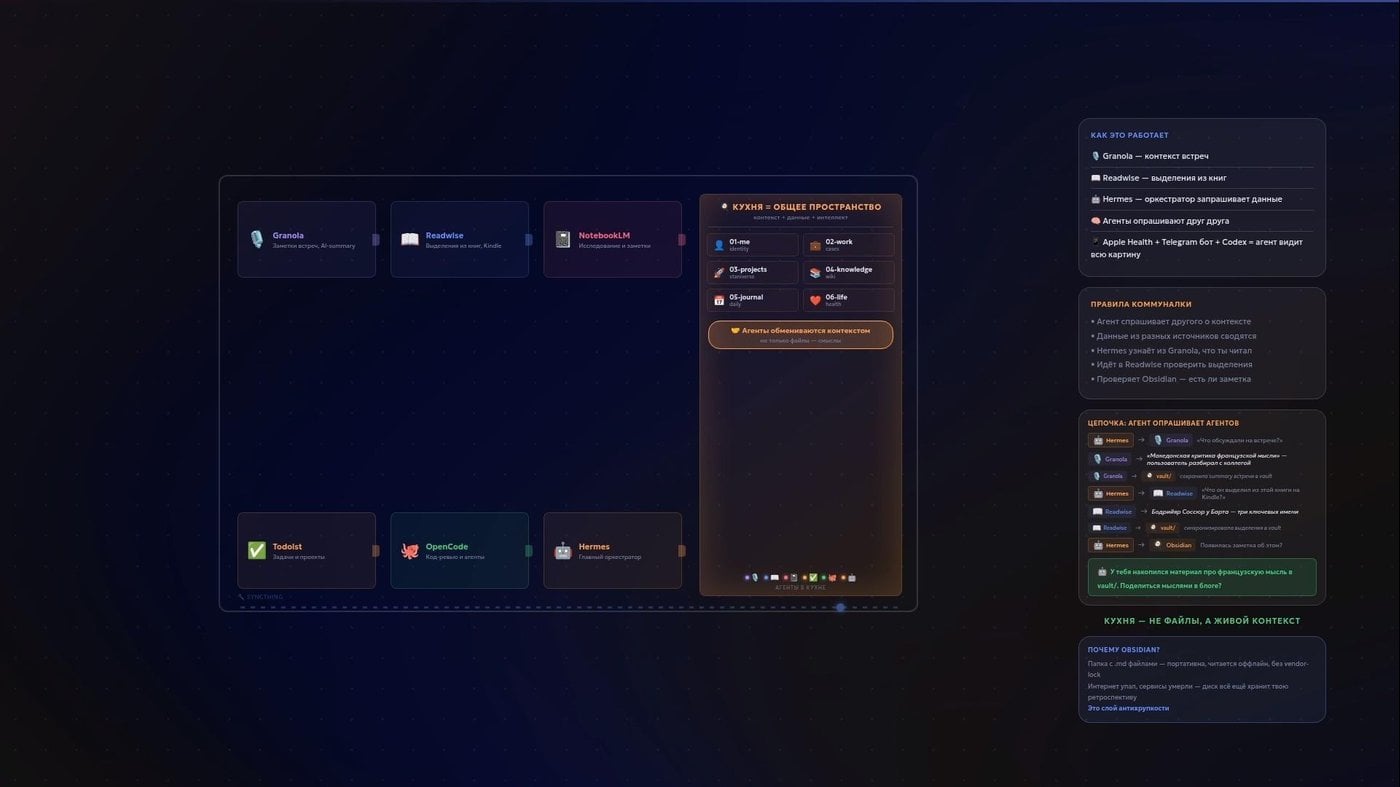
Когда устанешь, заводи, заводи. Всех. На кухню
И тут логично спросить: если агенты такие умные — сами пишут скрипты, ходят по API, собирают информацию — зачем вообще тащить всё это в какой-то Obsidian на домашнем ПК? Вот нужен мне какой-то помощник по здоровью, который поймёт что причина плохого сна и частых просыпаний с повышенным пульсом и весом - вечернее пиво с рёбрами, позавчерашнее сухое с сыром и малая физическая активность за период. Калории мне может считать отдельный бот в Телеге по фотке тарелки. Или как-то из FatSecret заберёт. Сон с тренировками трекает браслет и отправит в тот же Apple Health. Код моего несомненно многомиллиардного B2B AI SaaS проверит Codex, а умный агент-ассистент просто свяжет всё это в своей или внешней памяти, когда я спрошу. Зачем тут текстовая папка?
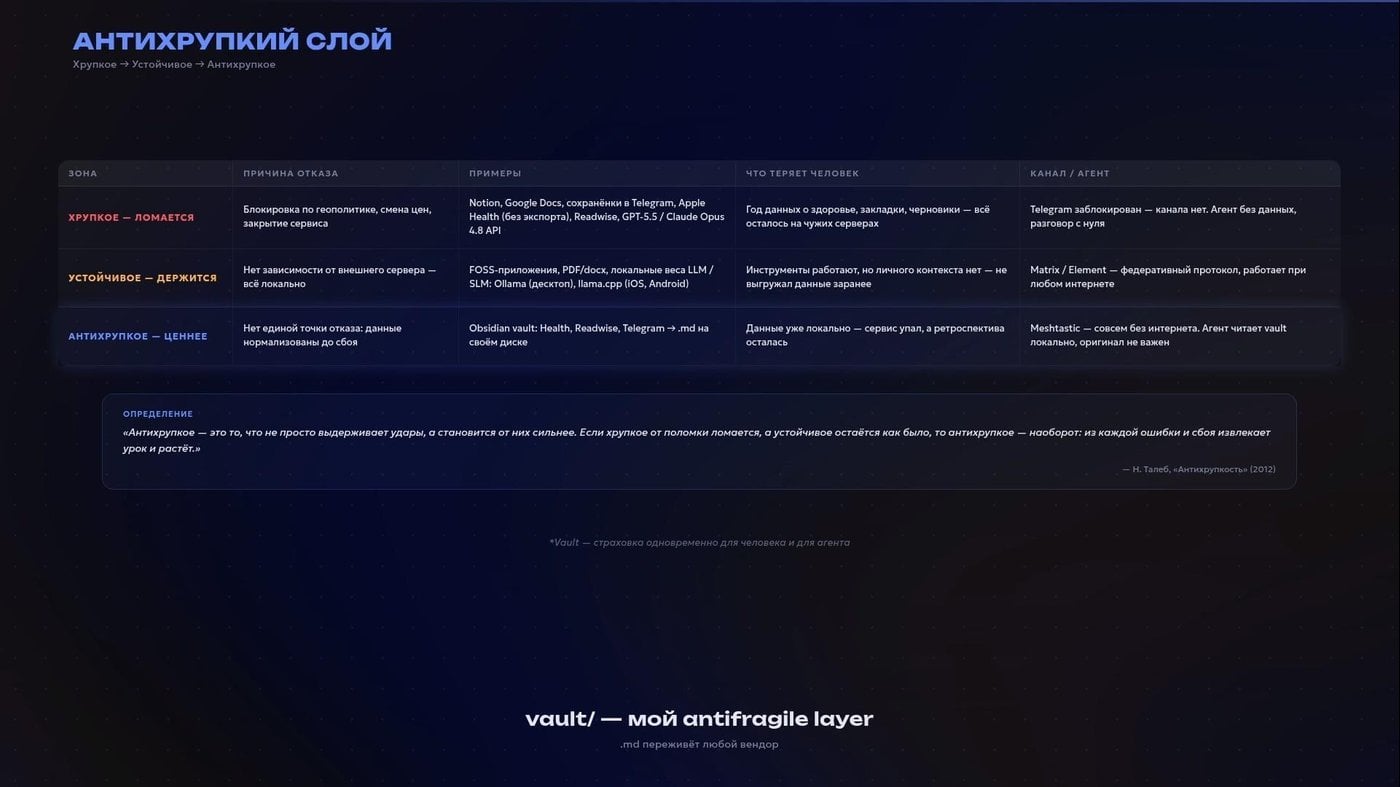
Попытался провести параллели с Н. Талебом
Затем, что Obsidian здесь — это не сколько база данных, сколько страховочный слой. Переносимый, читаемый без Интернета, не привязанный ни к одному облаку или вендору. Ваш слой антихрупкости. И если завтра интернет отключат, все сервисы лягут — на диске останется понятная текстовая ретроспектива.
Мы, к сожалению, не эльфийка Фрирен — у нас нет тысячи лет, чтобы набираться знаний методом проб и ошибок. Нам бы для начала хотя бы её качество сна получить! А там и цифровое бессмертие с доступом ко всем знаниям в облаке. Которе cloud и является сервером.
Как эта ваша папка со всем нажитым и сохраненным может эволюционировать дальше? Есть концепция, которую всё тот же Андрей Карпаты называет LLM Wiki. Суть в том, чтобы завести процесс, который между вашими сырыми пдфками, ссылками и моделью будет создавать синтетические статьи-понятия. Добавил источник — агент сам пошёл и обновил общую вики-статью про этот термин. Модель читает только её. Идею развивают фреймворки вроде obsidian-wiki.
Мне ближе более простой подход: договориться с агентом о правилах и шаблонах. Вот так обрабатывать книгу, сяк разбирать лекцию и вот этим образом создавать карточку источника. Так из созвона получать задачи, а вот по этому алгоритму из голосового сообщения получать черновик публикации.
С этим — возвращаемся к диплому.
Thesis as a Project (или как не открывать Word)
Тема моей ВКР: оптимизация природопользования и охраны окружающей среды в Кировской области.
Начнем с начала. Есть методичка кафедры в PDF. Я открыл её в Google AI Studio и попросил извлечь структурированный список требований. Можно было и через агента, но я экономил токены. Сегодня я попробовал бы провернуть это через навык book-to-skill, который должен очень не нравиться издательствам и авторам на роялти.
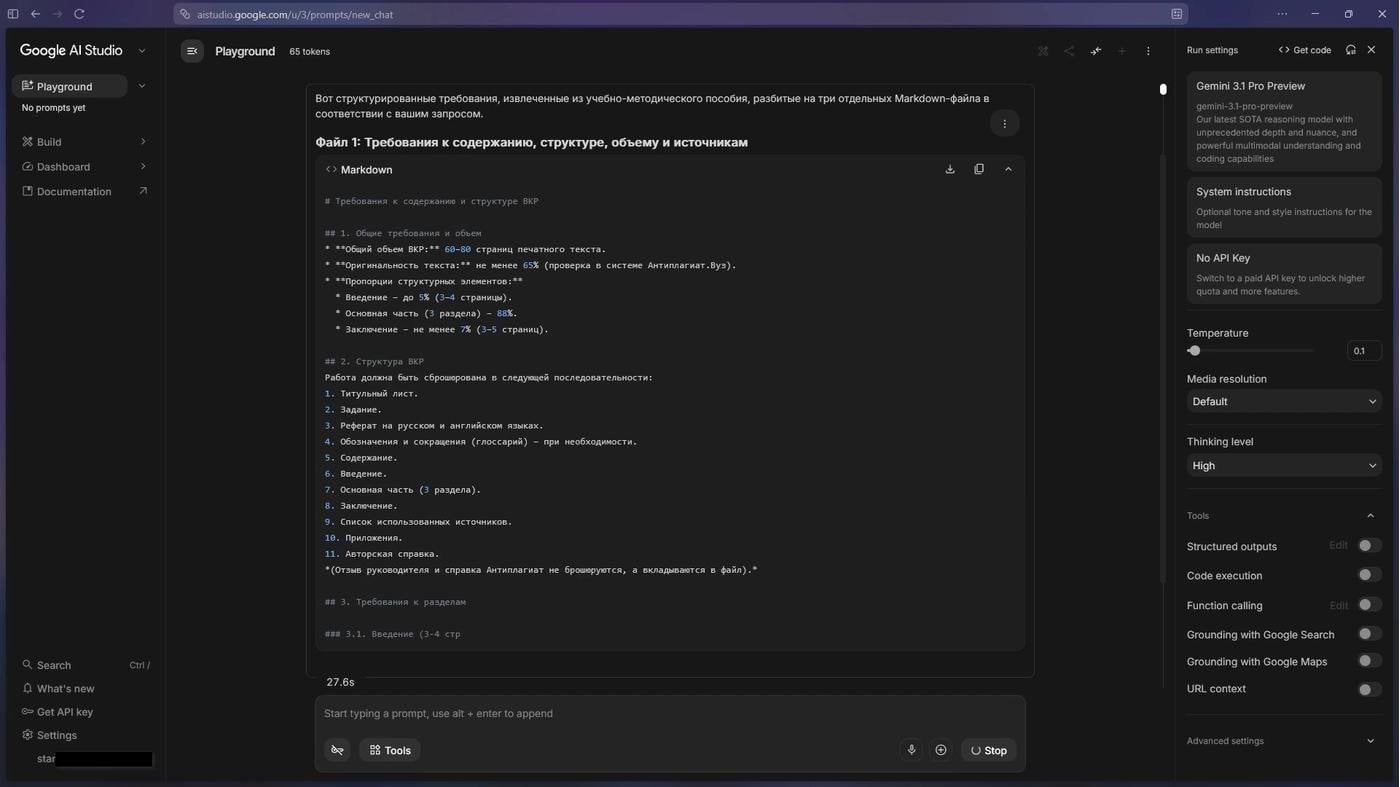
Чуть-чуть сэкономил
Руками я собрал структуру папок проекта. Вернее скриптом. Отдельная папка для требований, отдельная — для результатов поиска, ещё одна — для глав. И папка для Python-скриптов — они собирали финальный файл и считали математику.
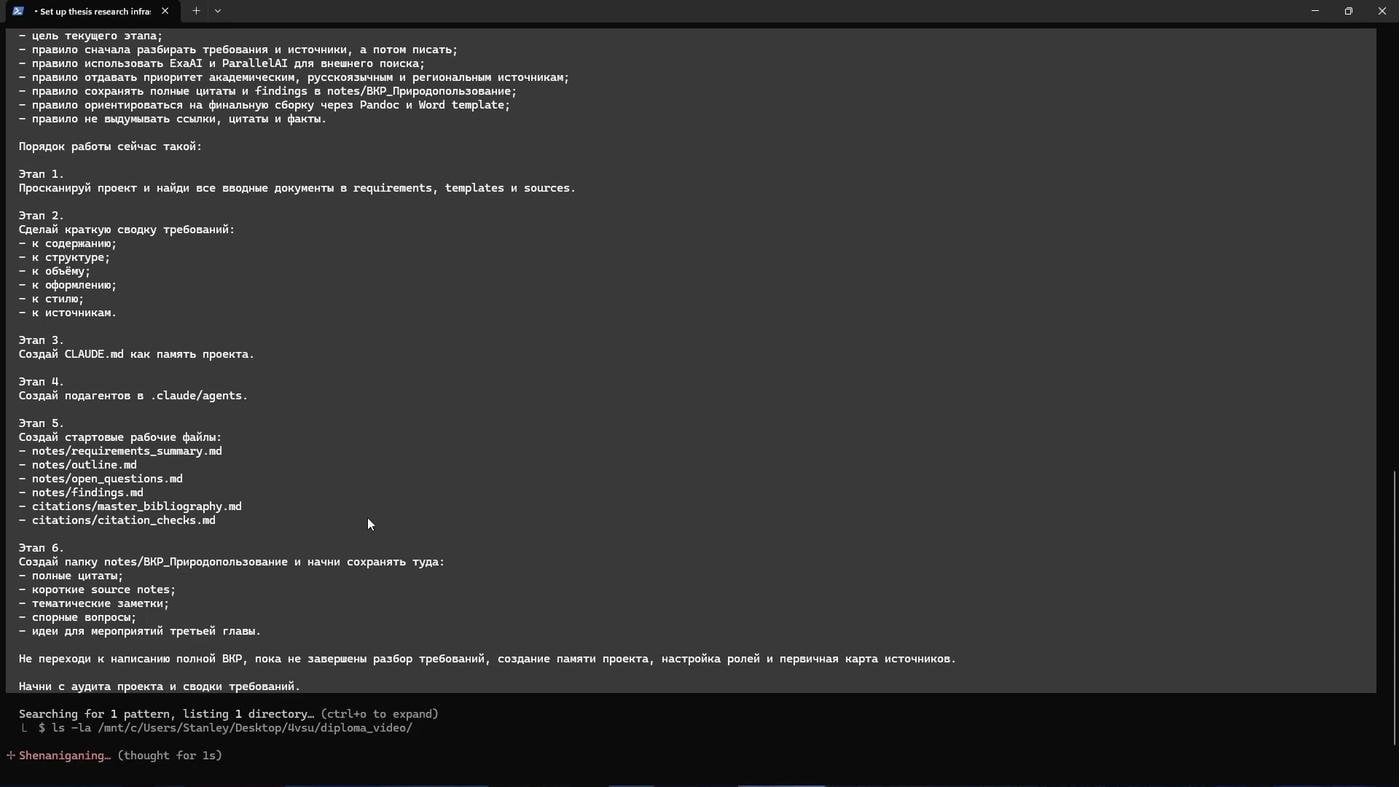
Довольно черновое воссоздание того процесса
У меня был субагент для поиска фактуры через Parallel AI и Exa AI. Просил его уделять внимание КиберЛенинке и eLIBRARY, а найденное валидировать через DOI. Был тот, кто помогает писать под жанр с его ограничениями. И дополнительно прогонял текст на популярные маркеры AI-генерации из Википедии через тот самый навык humanizer.
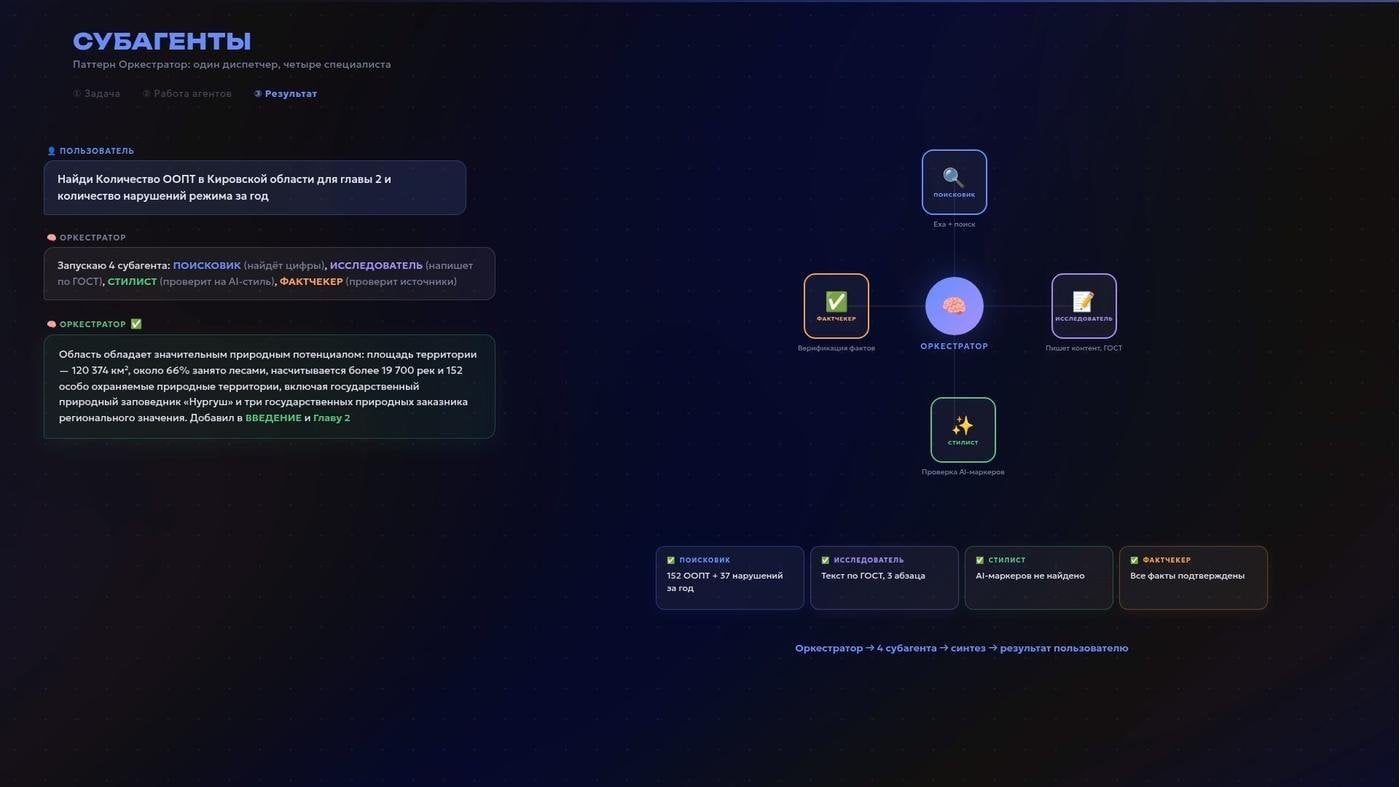
Как оно происходило
В третьей главе я предлагаю снимать VR-фильмы про заповедные территории своего региона, закупить XR-гарнитуры и возить показывать труднодоступную природу в школы. Для этого мне нужны были зарубежные источники о влиянии иммерсивных технологий на запоминание.
Я отправляю агента, переключаюсь на другую задачу, а он тем временем ищет, читает, синтезирует и возвращается со списком реальных источников. Я читаю, принимаю — или прошу копать глубже.
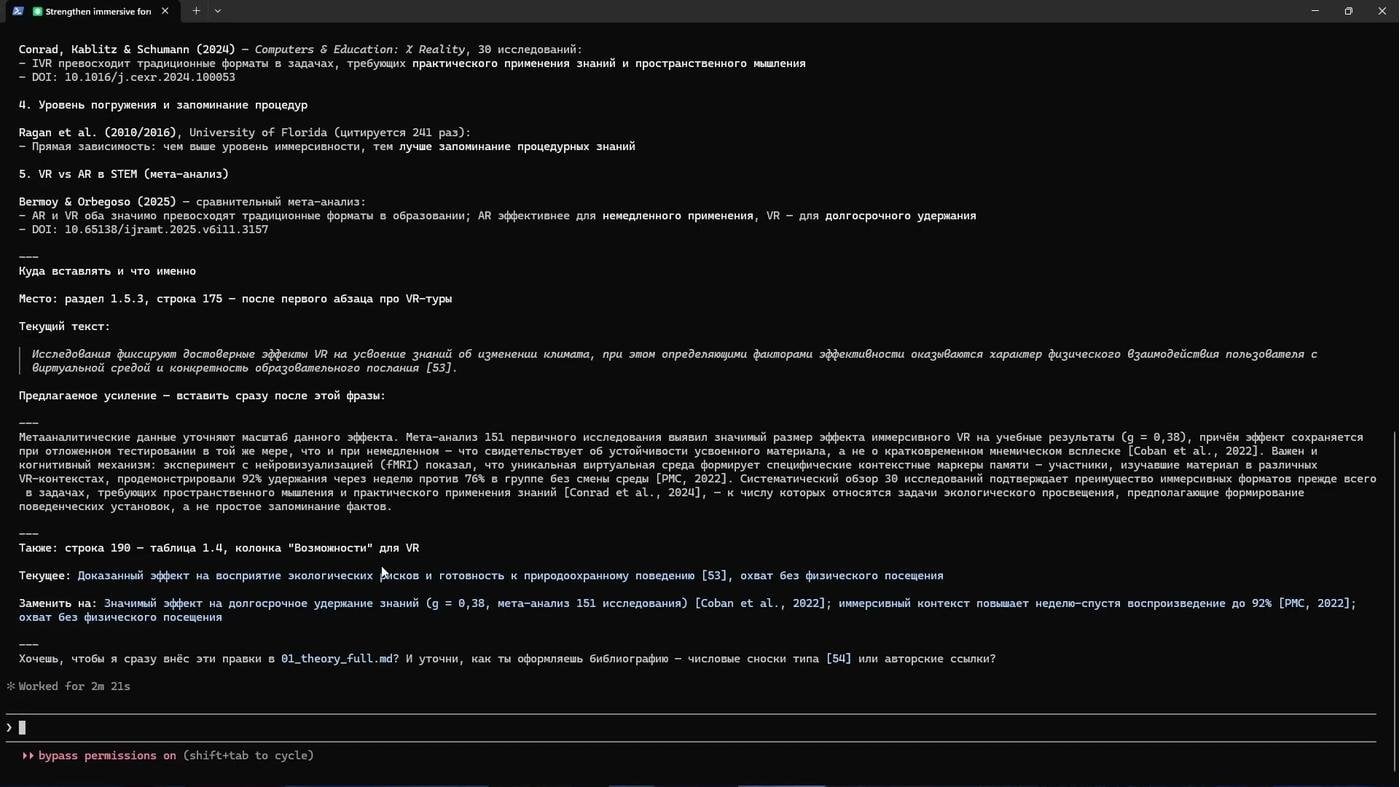
Подтвердил мета-анализом идею своего предполагаемого проекта
Одно из предлагаемых мной мероприятий — создание телеграм-бота с маршрутами эко-троп и геймификацией процесса отправки сигнала о нарушениях. В нём сразу было слабое место: Telegram уже заблокирован в ряде стран, и разговоры о блокировке у нас велись. На защите за такое вполне могут уцепиться. Агент этого не заметил. Человек — заметил.
Поставил задачу: исследуй риски блокировки, посмотри аудиторию этого и тех трёх букв, в которые нас всех посылают, предложи, как с этими рисками мы будем работать. Агент ушёл, вернулся с данными. По итогам мы пересобрали позицию: конструировать Mini App, который можно открыть и в браузере. Смета от этого не разваливается.
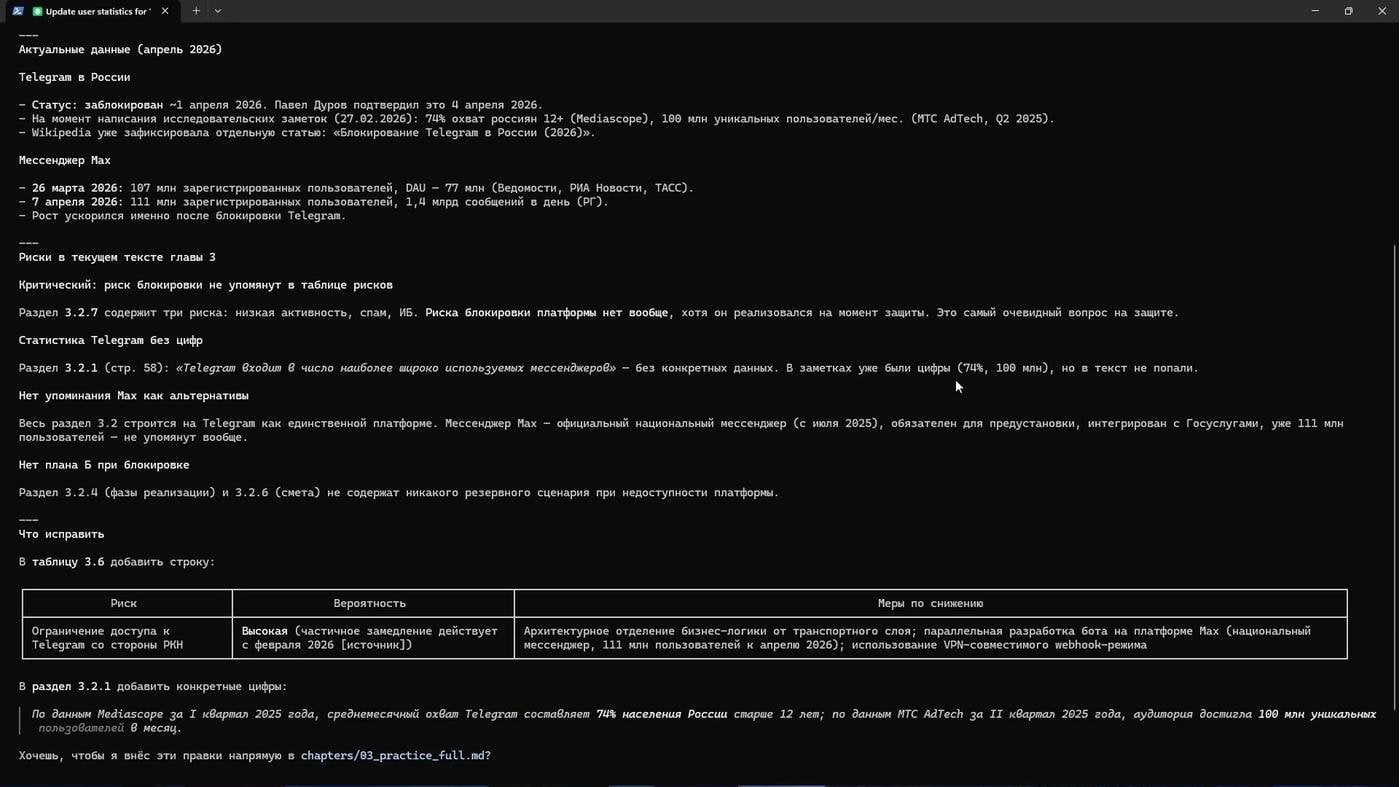
Дилемма из трёх букв
Это пример моего главного принципа. Агент принёс данные и аргументы. Решение принял я. Слабое место заметил тоже не он. Я тот самый «человек в петле», пока не в прямом и грустном смысле слова.
Каждое изменение фиксировалось в git. Имба как сохранения перед боссом, чтобы вместо кучи файлов final_final.docx была нормальная история. Я даже удивился, насколько для натурального языка это так же удобно, как и для языков программирования.
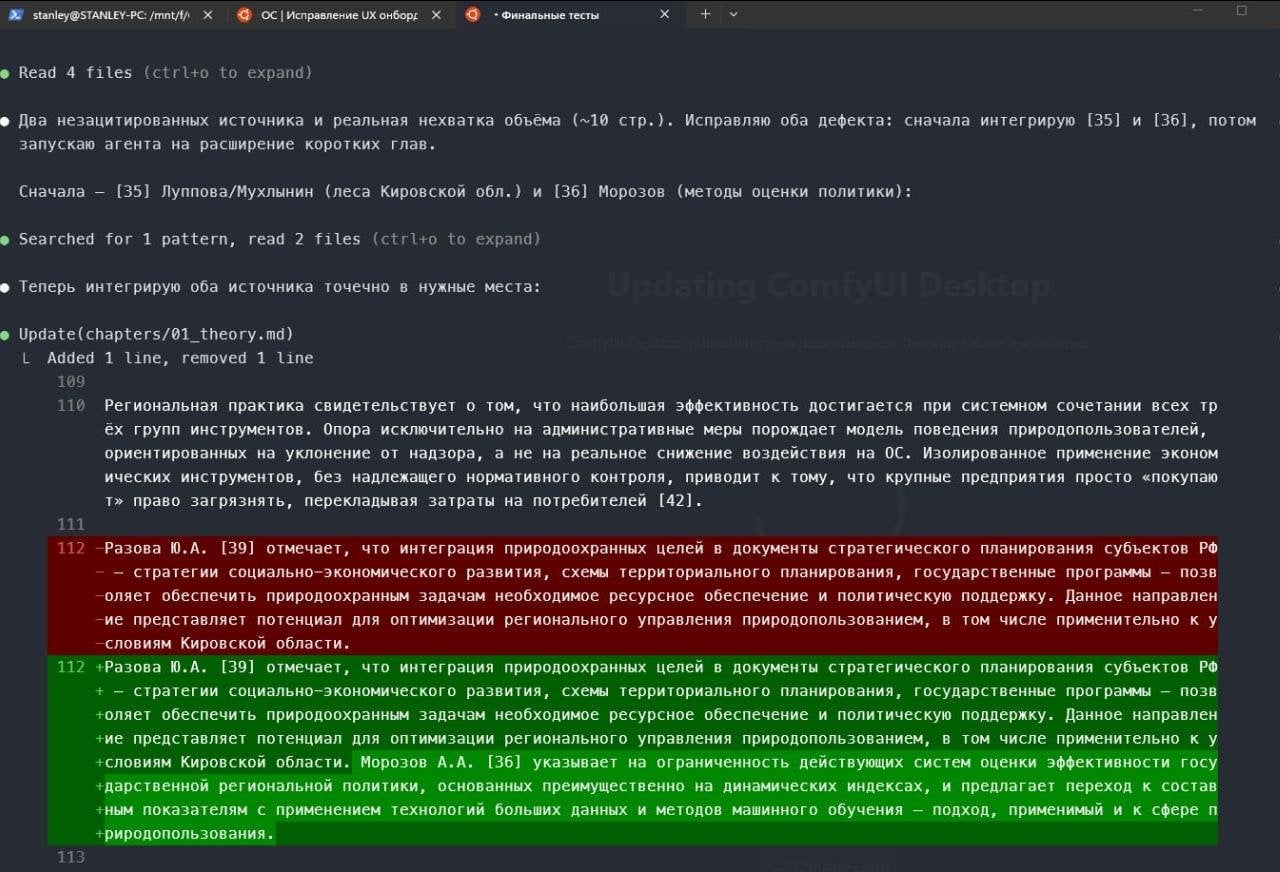
Как ощущается Git для натурального языка
Доцент Йельской школы менеджмента(https://som.yale.edu) Пол Голдсмит-Пинкем в своей серии постов на Substack про использование кодинговых агентов для эмперических исследований советует периодически сохранять текущий прогресс в отдельном progress.md файле и начинать свежую сессию, чтобы избежать деградации ответов и не упираться в контекстное окно. Я к этому присоединяюсь: не всегда встроенная команда compact даёт такой же чистый результат, как новая свежая сессия.
В главе второй нужна была схема оргструктуры. Я послал агента на официальный же сайт места прохождения преддипломной практики в раздел «Контакты» и попросил создать диаграмму прямо в markdown через Mermaid. Потом её легко перегнать в картинку. А таблицы с данными агент собирал из источников, которые загружались в NotebookLM и забирались через CLI-решение от сообщества. Здесь снова стоит перепроверять математику с Python, и убедиться в отсутствии каши из процентов и процентных пунктов на соседних строках.
Вся работа у меня была в markdown. На выходе нужен был Word с ГОСТ-оформлением. Попросил агента написать скрипт сборки с помощью Pandoc — он склеивал текст в нужном порядке и собирал финальный .docx одной командой, сверяясь по форматированию с шаблоном моей какой-то старой курсовой. С презентацией для защиты примерно та же история: из требований методички и записи вебинара разобрались со структурой выступления, количеством слайдов и необходимостью верстать в 4:3. Проговорил агенту свои пожелания и акценты, через какое-то время получил отдельно черновик текста и файл PowerPoint.
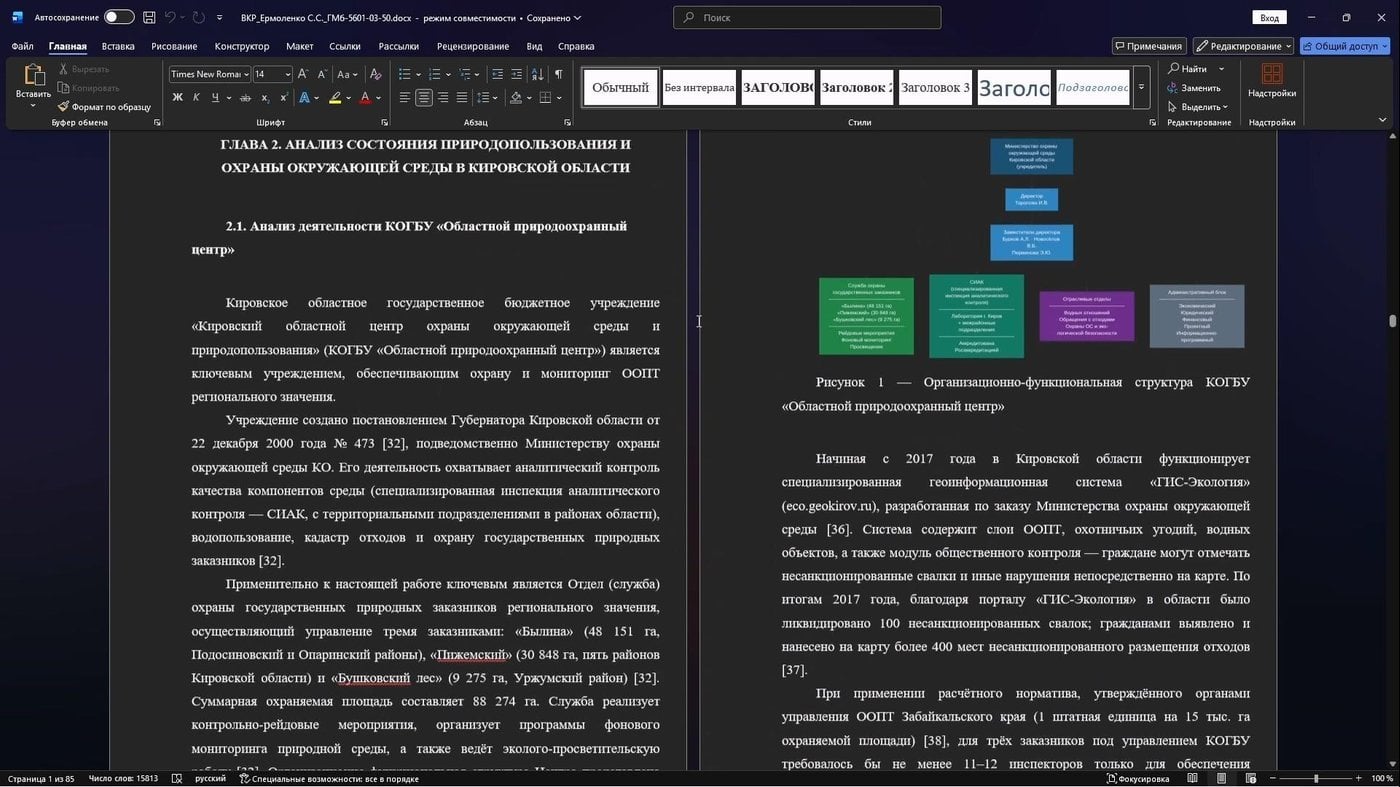
Mermaid картинкой встала. И перекрёстные ссылки работают!
У того же Claude теперь есть прямая интеграция и готовые навыки работы с и в Microsoft Office. На случай если вам всё ещё страшно. А если работа больше про формулы, есть смысл использовать LaTeX или Typst.
Вот так и получилось то, с чего я начал. Диплом защищён на «отлично». Word действительно почти не открывался, а правки удобнее оказалось давать голосом.
И я точно не открыл здесь чего-то нового про использование агентов. Ресёрчем по GitHub нашёлся открытый репозиторий Алессандро Кафорио из Боккони, защитившего магистерскую с похожей архитектурой. И Qiongli с тем же принципом, упакованном в готовый порядок работы. У них звёзд ещё меньше, чем на моих постах и сторисах, но посмотреть и возможно вдохновиться на своё ничего не стоит.
Human in the Loop: Архитектор или читер?
Честно и этично ли это всё?
Каждое решение в работе, удачное, косячное или спорное, было моим. Агент предлагал варианты, а я их изучал, принимал или отправлял на доработку со своими комментариями и дополнительными задачами. Поэтому во время допуска и защиты я без проблем отвечал на любые вопросы по содержанию работы.
Идеи в главе с мероприятиями тоже мои и тесно завязаны на моих интересах. Но я усиливал эти идеи с помощью ИИ. Примерно так же, как стендап-комики разгоняют материал с камеди-бадди.
Если уходить в спорные аналогии…хороший архитектор не кладёт каждый кирпич сам. Он проектирует конструкцию, выбирает материалы, проверяет расчёты — и отвечает за результат. Инструменты — какие и чьи угодно, решения — за мной. Комиссия смотрит на проект, а не на то, кто месил раствор.
Мой диплом не был написан вместо меня. Он был собран в системе, где источники, заметки, голос и агенты работали вместе. И вот это, по-моему, тот самый навык, который стоит осваивать уже сейчас: не просить нейросеть сделать за тебя (миллион), а выстроить вокруг себя систему, где думать легче, проверять проще, а хаоса меньше.
Я не хочу продавать вам мечту Сыроежкина, где вкалывают роботы, а человек счастлив ничего не делая. По-моему, здесь не про это. Вы не перестаёте работать. Просто время освобождается для того, чтобы замахнуться на задачи, на которые раньше бы просто не хватило ни рук, ни сил.

Нарисовал в ChatGPT, на этой старой башне (ладно, колокольне) тоже бьют часы
По данным опроса Anthropic, среди инженеров около 27% задач они бы вообще не начали без ИИ-инструментов. Не «ускорили», а «даже не начали бы». И вот это, кажется, точнее всего описывает происходящее. Времени всё так же «в обрез», а человеку для счастья вернуться бы куда-то в 2019-й.
С другой стороны, в 2026-м, имея доступ к инструментам и пытливый ум можно успеть много классного. Когда я был школьником, то, если семейный бюджет позволял, ходил на курсы по HTML. Тогда сама мысль о том, что можно правда научиться делать свой сайт, казалась чем-то невероятным.
Давно это было, конечно :(
Сегодня ребята 10–12 лет прекрасно знают, как попасть в Roblox вопреки любым блокировкам. И что особенно радует — за пару академических часов занятий с кем-то вроде меня уже собирают свои первые лендинги с мини-играми, которые выглядят сильно лучше, чем мои первые страницы, где столько времени занимал только поиск пропущенной закрывающей скобки. А ещё оказалось классной идеей брать школьные учебники и просить LLM-ки делать из уроков HTML-игры.
На фоне всего происходящего меня такие вещи почему-то очень вдохновляют. Надеюсь, и вас тоже.
По теме создания ИИ-компаньонов и виртуальных собеседников у меня есть ещё один большой материал: ИИ-вайфу на 14 февраля — инструкция по применению (и созданию).
Как-то так. Спасибо, что дочитали до конца.
Из Вятки, с любовью